
티스토리 뷰
[ICML 2022] VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
금복이 2024. 4. 6. 18:57Introduction
Two mainstream architectures are widely used in previous work.
- Dual-stream : encode images and text separately. Modality interaction is handled by the cosine similarity of the image and text feature vectors. This architecture is effective for retrieval tasks, especially for masses of images and text
- Representative model : CLIP, ALIGN
- Limitation : Its shallow interaction is not enough to handle complex VL tasks (e.g., visual reasoning)
- Fusion-encoder : this achieves superior performance on VL classification tasks
- Representative model : ViLT, ALBEF (ALBEF uses both dual-stream and fusion-encoder)
- Limitation : heavy model (transformer), and it requires to jointly encode all possible image-text pairs to compute similarity scores for retrieval tasks (slower inference speed than dual-encoder arch)
VLMo (Vision-Language pretrained Model) that can be used as either a dual encoder to separately encode images and text for retrieval tasks, or used as a fusion encoder to model the deep interaction of image-text paris for VL classification tasks (이 설명만 보면 ALBEF의 구조와 같음)
- We reuse Multiway Transformer with the shared parameters for differnet purposes, i.e., text-only encoder, image-only encoder, and image-text fusion encoder
- 하지만, ALBEF와는 다르게 이미지 인코더, 텍스트 인코더, 멀티모달 인코더(fusion)의 Multihead Self-Attention 가중치를 공유시킴
Methods
Input Representation
- Image Representations : ViT와 동일. [I_CLS]라고 하는 learnable special token을 삽입함. Image input representations are obtained via summing patch embeddings, learnable 1D positional embeddings, and image type embedding
- Text Representations : BERT와 동일. WordPiece tokenizing, [T_CLS]라고 하는 start-of-sequence token을 맨 앞에, special boundary token [T_SEP]를 맨 뒤에 삽입해줌. 마찬가지로 positional embeddings, text type embedding 필요
- Image-Text Representations : We concatenate image and text input vectors
Stepwise Pre-Training
VLP 학습을 위한 (이미지, 텍스트) 데이터에 비해, (이미지), (텍스트)의 개별적인 데이터는 매우 많음. 이러한 데이터를 학습함으로써 VLP 성능 개선을 시킴. 보통 VLP 데이터에서의 텍스트는 짧은 캡션이기 때문에, 이렇게 개별적인 modality의 방대한 데이터로 학습시키는 것이 generalization on complex pairs를 개선시킨다고 언급함.

V-FFN, L-FFN, VL-FFN은 각각 vision, language, vision-langauge modality에 대한 expert의 역할을 함. two linear transformations and an activation 구조임.
- image-only data로 이미지 인코더를 사전학습 함. 이 과정은 pre-trained BEiT-base 모델로 VLMo의 attention module과 V-FFN의 가중치를 초기화 시키는 것으로 완료됨
- text-only data로 L-FFN을 학습시킴. 이때 신기한 건 attention module의 가중치를 고정시킨다는 것임. 만약 attention module까지 학습시킨다면 vision knowledge에 대한 catastrophic forgetting이 발생하기 때문이라고 함. text-only data에 대한 학습은 MLM로 함
- image-text data로 VLP를 진행함. 구체적으로, vision expert는 이미지를 처리하고, language expert는 텍스트를 처리함. 둘의 output을 (아마도 concat?) vision-language expert의 입력값으로 주는 것
Pre-training Tasks for Vision-Language Expert
- Image-Text Contrastive Learning : $N$개의 (이미지, 텍스트) 페어가 배치로 들어옴. 그렇다면 $N$개의 positive pairs와 $N^2 - N$개의 negative pairs를 얻는 것임. Vision expert의 각 이미지의 [I_CLS] 최종 임베딩, language expert의 각 텍스트의 [T_CLS] 최종 임베딩으로 contrastive learning을 진행함 (simCLR)
- Masked Language Modeling : BERT의 MLM 방식을 그대로 따르며, whole word masking을 적용함. language expert를 학습하기 위한 MLM과 다른 점은, 토큰 복원을 위해 vision clue를 이용할 수 있다는 것임
- Image-Text Matching : vision-language expert의 final hidden vector of the [T_CLS]를 (이미지, 텍스트) 페어에 대한 전체적인 표현으로 취급함. ALBEF에서 영감을 받아, ITM을 위해 contrastive encoder를 이용한 hard negative mining을 함
Fine-Tuning VLMo on Downstream Tasks
- Vision-Language Classification : We use the vision-language expert's final encoding vector of the token [T_CLS] as the representation of the image-text pair, and feed it to a task-specific classifier layer to predict the label
- Vision-Language Retrieval : During fine-tuning, VLMo is optimized for image-text contrastive loss. During inference, we compute representations of all images and text, and then use dot product to obtain image-to-text and text-to-image similarity scores of all possible image-text pairs (즉, vision-language expert를 쓰지 않음. CLIP과 동일하게)
Experiments
Pre-Training Setup
기존 연구들을 따라, Conceptual Captions (CC), SBU Captions, COCO, Visual Genome (VG)를 합친 4M 데이터셋으로 VLP를 진행
- VLMo-Base (175M) : 12-layer Transformer blocks with 768 hidden size and 12 attention heads
- Vision-language expert is the top-two layers of whole model
- VlMo-Large (562M) : 24-layer Transformer blocks with 1024 hidden size and 16 attention heads
- Vision-language expert is the top-three layers of whole model
For images, the input resolution is $224 \times 224$ and the patch size is $16 \times 16$ during pre-training. We apply RandAugment to the input images. We pretrain the models for $200k$ steps with $1024$ batch size. 더 세부적인 하이퍼파라미터는 논문 참고.
Results

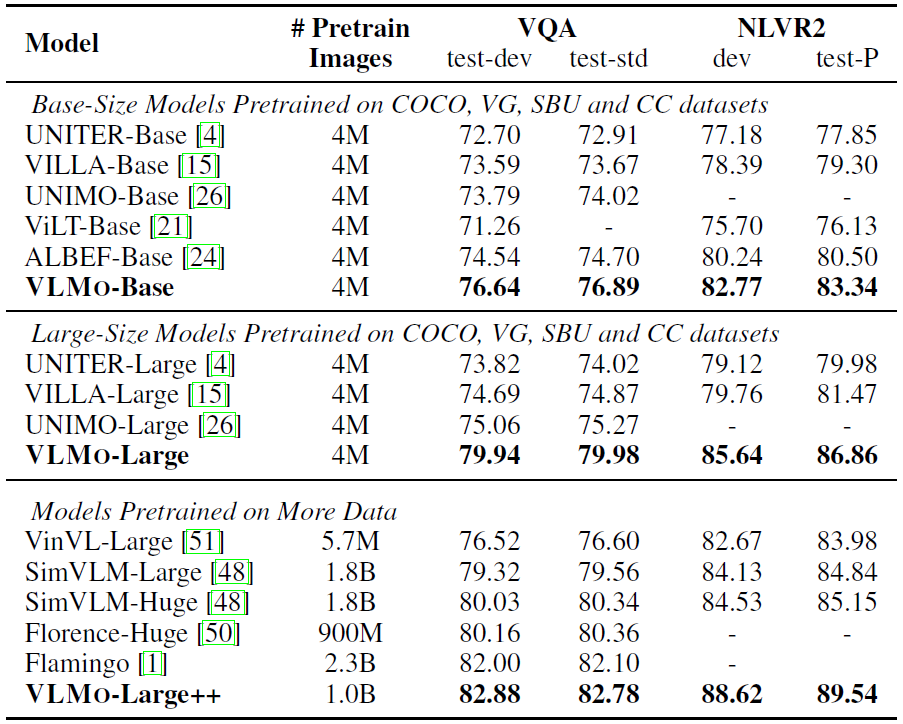
Ablation Study



Std TRM은 일반적인 트랜스포머, Multiway-VLExp는 Multiway 이긴 하지만 vision-language expert (fusion encoder)를 쓰지 않았다는 의미이다 (VlExp를 없앤거면 fusion이 일어나지 않는데, NLVR2 파인튜닝을 위한 모델 구조를 어떻게 설정한 건지 잘 모르겠다..)
Conclusion
- Sharing self-attention at Multiway transformer enables aligning different modalities (It works like early fusion)
- Stepwise pre-training leverages large-scale image-only and text-only corpus greatly improves vision-language pre-training