
티스토리 뷰
1. Abstract
- Gated Multimodal Unit (GMU)를 소개한다. 이는 어느 딥러닝 모델이라도 내부에 쉽게 적용될 수 있는 유닛이며, 서로 다른 모달리티의 데이터의 조합으로 intermediate representation을 찾으려는 목적을 갖는다.
- Multiplicative gates를 이용하여 여러 모달리티가 GMU의 activation에 어떻게 영향을 끼칠지(기여할지)는 결정하는 법을 배운다.
- MM-IMDb라는 데이터셋을 공개했는데, 이는 저자들이 아는 한 가장 큰 멀티모달 영화 장르 예측 데이터셋이라고 한다.
2. Introduction과 Related work에 포함된 GMU의 특징
- Input-dependent한 gate-activation 패턴을 배운다. 즉, 인풋의 특징에 맞게 각 모달리티가 GMU의 아웃풋에 얼마만큼 기여를 할 지 결정한다.
- GMU는 컴포넌트이기 때문에 모델의 final task(e.g. 분류, 회귀, 비지도 학습, etc)와는 독립적이다. 즉, 어떤 태스크를 위한 모델에도 잘 적용될 수 있다. GMU는 objective function의 gradient로 end-to-end 하게 학습된다.

본 논문에서 다루고자 하는 태스크는 영화 장르 예측(multi-lable prediction)이다. 인풋 모달리티는 영화의 포스터(visual)와 줄거리(text) 두 가지가 있다. Figure 1에선 visual, text 모달리티를 개별적으로 학습한(즉, unimodal) 딥러닝 모델의 예측을 보여준다. 빨간색 예측은 False Positive이며, 파란색 예측은 True Positive이다.
3. Methods
3. GMU for multimodal fusion

GMU의 구조는 LSTM이나 GRU만큼 복잡하지는 않다. Figure 2의 (a)는 일반적인 GMU의 구조이며, (b)는 인풋 모달리티가 2개일 때 맞춤 설계된 GMU이다.
모달리티가 총 $N$개 있다고 하자. $x_{i}$는 $i$번째 모달리티의 피처 벡터이고, $\sigma_{i}$를 $i$번째 모달리티가 GMU의 출력값에 얼마나 기여할 것인지를 출력하는 함수이다. 저자들은 기본적으로 logistic function($f(x) = 1 / (1 + e^{-x})$)를 썼다.
GMU의 출력값($h$)은
$ \sigma_{1}(W_{\sigma 1}[x_{1}, ... , x_{N}]) \textbf{tanh}(W_{1}x_{1}) + ... + \sigma_{N}(W_{\sigma N} [\sigma x_{1}, ... , x_{N}]) \textbf{tanh}(W_{N}x_{N})$이다.
게이트 $\sigma_{i}$는 모달리티 $i$의 기여도를 결정하기 위해 모든 모달리티의 피처 벡터를 고려한다. 이는 특정 샘플의 internal encoding에 dependent하게 모달리티의 기여도를 결정하므로 유연하다고 볼 수 있다.
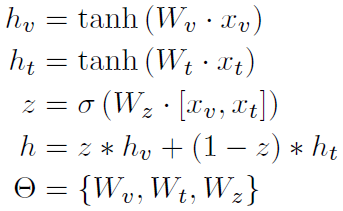
영화 장르 예측 태스크처럼 모달리티가 2개인 경우에는 게이트가 한 개인 구조로 설계할 수 있다. 게이트의 출력값을 $z$라고 하면, 모달리티1에는 $z$, 모달리티2에는 $(1-z)$를 기여도로 사용하면 되기 때문이다. 이러한 트릭으로 게이트에 쓰이는 매개변수를 줄일 수 있기 때문에 더 적은 매개변수를 가진 GMU를 만들 수 있다.
GMU에 쓰인 연산($\textbf{tanh}(\cdot), \sigma(\cdot), \textbf{concat} [\cdot , \cdot]$)은 모두 미분 가능하기 때문에 전체 모델 안에서 gradient를 통해 다른 뉴럴 네트워크와 함께 업데이트 된다.
3.2 Text Representation
이후 실험에서 텍스트 모달리티, 이미지 모달리티, 멀티모달리티 표현을 가지고 영화 장르 분류를 수행하는데, 그때 각 유니모달일 때 표현을 어떻게 만들었는지 설명한다. 텍스트(영화 줄거리)를 하나의 표현으로 만드는 방법으로 n-gram, word2vec의 두 가지 방법을 사용했다. n-gram에 대해선 잘 모르지만, 텍스트의 맥락이나 단어 사이의 관계를 잘 모델링하지 못 한다고 설명하는 것을 보아 오래 전에 나온 알고리즘같다. word2vec은 비지도 학습 알고리즘이며, 각 단어의 임베딩을 맥락에 맞게 벡터로 임베딩한다. 저자들은 영화 줄거리를 구성하는 모든 단어의 word2vec 표현을 평균하여 표현으로 사용했다고 한다. word2vec은 구글의 pretrained 모델을 가져다가 썼다. wor2vec 임베딩은 additive compositionality가 존재하여 임베딩끼리 더하고 빼는 연산이 의미를 가지는데, 줄거리를 구성하는 모든 단어의 임베딩을 더하면 값이 너무 커져 뉴럴 네트워크의 인풋으로 적절하지 않아 평균을 사용했다고 한다.
3.3 Visual Representation
이미지 표현도 두 가지를 쓴다. 첫 번째는 이미지넷 데이터를 사전학습 한 VGG 모델이 주는 피처이며, 두 번째는 5 CNN +1 MLP로 구성된 모델을 from the scracth로 학습시켰을 때 그 모델이 주는 피처이다.
4. Experimental Evaluation
4.1 Experimental setup
각 장르에 대해 학습, 검증, 테스트 데이터셋의 비율을 6:1:3으로 맞췄다고 한다. multi-class 분류 (정답 레이블이 one-hot vector)와 multi-label 분류 (정답 레이블의 여러 원소가 1일 수 있음) 모델은 다르다. multi-label 분류 모델의 성능을 평가하는 여러 $f_{1}$메트릭이 있는데, 각 메트릭은 성능의 특정 부분을 집중적으로 평가하므로 메트릭에 따라 모델의 성능이 상이할 수 있다. 그래서 저자들은 multi-label 분류에서 많이 쓰이는 4가지 메트릭에 대해 모델의 성능을 평가한다.
- $f_{1}^{sample} = \cfrac {1} {N} \sum\limits_{i=1}^{n} \cfrac {2 \times \lvert \hat{y}_{i} \cap y_{i} \rvert} {\lvert \hat{y}_{i} \rvert + \lvert y_{i} \rvert}$ : 각 샘플마다 정답 레이블과 모델의 예측 레이블의 자카드 유사도를 구하여 평균
- $f_{1}^{macro} = \cfrac {1} {Q} \sum\limits_{j=1}^{Q} \cfrac {2 \times p_{j} \times r_{j}} {p_{j} + r_{j}}$ : 각 장르마다 $f_{1}$ 값을 구하여 평균
- $f_{1}^{weighted} = \cfrac {1} {Q^{2}} \sum\limits_{j=1}^{Q} \cfrac {2 \times p_{j} \times r_{j}} {p_{j} + r_{j}}$ : 각 장르마다 $f_{1}$ 값을 구하고, 장르 당 정답 레이블 수로 가중합
- $f_{1}^{micro} = \cfrac {2 \times p^{micro} \times r^{micro}} {p^{micro} + r^{micro}}$ : $p^{micro}$는 모든 장르에 대해 $TP$와 $FP$를 계산해서 얻은 precision이며, $r^{micro}$도 이와 같은 재현율
4.4 Multimodal Representation
유니모달(텍스트, 이미지)에 대한 표현을 무엇으로 할 건지 정했으므로, 이제 GMU와 비교 할 멀티모달 표현 방법들을 정할 차례이다. 저자들은 4가지의 멀티모달 표현 방법을 제시한다.
- Average probability : late-fusion으로도 불리며, unimodal 모델의 최종 출력값(softmaxed)에 평균을 취한다.
- Concatenation : unimodal 모델의 피처를 이어붙여 사용한다. MLP가 이를 인풋으로 받아 학습한다.
- Linear sum : unimodal 모델의 피처를 같은 공간으로 매핑시키기 위해 각 표현에 선형 변환을 취한다음 더해준 표현을 사용한다. MLP가 이를 인풋으로 받아 학습한다.
- MoE(mixture of experts) : GMU가 하는 역할과 비슷한 것 같다. unimodal model(MoE에선 MLP이다)을 하나의 expert로 취급했을 때, 각 expert의 결괏값을 얼만큼 믿을지를 결정하는 게이트가 존재한다. 즉, 여러 expert의 결과를 가중합하여 사용한다.
5. Result
5.1 Evaluation over synthetic data
각 샘플을 분류하는 태스크가 있다고 하자. 과연 샘플마다 어느 모달리티가 더 많은 정보를 기여하고 있는지 GMU는 인지할 수 있을까? 가령 본 논문처럼 영화 장르를 맞추는 태스크라고 하자. 샘플1은 포스터보다 줄거리가 더 많은 정보를 담고 있고, 샘플2는 포스터가 줄거리보다 더 많은 정보를 담고 있다고 하자. GMU는 샘플1에 대해선 포스터에, 샘플2에 대해선 줄거리에 더 많은 가중치를 부여해야 한다.
GMU의 이러한 능력을 평가하기 generative model을 이용한 synthetic task 실험을 수행했다.
- 모델은 인풋으로 $x_{v}, x_{t}$를 받아 $0$ 또는 $1$로 예측을 수행한다.
- 정답 $C$는 binary ramdom variable이다.
- $x_{v} = My_{v} + (1-M) \hat{y}_{v}, x_{t} = (1-M) \hat{y}_{t} + My_{t}$인데, $\hat{y}_{v}, \hat{y}_{t}$는 퀄리티가 매우 낮은 source여서 모델의 예측에 도움을 주지 못한다.
- $M$은 binary random variable이다.
각 샘플에서 하나의 모달리티만 기여를 하고, 다른 하나의 모달리티는 기여하지 않는다고 생각하면 된다. 그리고 어떤 모달리티가 기여를 하게 되는지는 잠재 변수 $M$에 의해 결정된다. GMU의 출력값에 sigmoid function을 취하여 예측 모델을 학습시켰을 때, GMU 게이트의 활성화와 $M$ 사이의 상관관계가 $1$이 나왔다고 한다. 이 말은 GMU가 인풋 $x_{v}, x_{t}$만 관측하고도 보이지 않는 잠재 변수인 $M$을 학습했다는 뜻이다.

Figure 7의 왼쪽 그림은 게이트의 활성화를 인풋에 대하여 나타낸 것이다. 활성화의 경계가 뚜렸한데, 회색 영역은 게이트의 활성화를 보여준다. 회색 영역에 포함된 샘플들은 모두 $x_{t}$가 더 많은 정보를 갖고 있으며($M = 0$), 흰 영역에 포함된 샘플들은 모두 $x_{v}$가 더 많은 정보를 갖고 있다($M = 1$). 게이트는 $M$ 값에 따라 어떤 모달리티가 많은 정보를 포함하고 있는지 잘 맞추는 활성화 경계를 찾았다.
오른쪽 그림은 모델의 클래스 결정 경계를 보여주는데, 흥미로운 점은 이러한 경계도 게이트의 활성화 경계를 기반으로 그려진다는 것이다.
5.2 Genre classification result

영화 장르 예측 태스크에 대한 결과이다. 모달리티는 크게 멀티모달, 텍스트, 이미지로 나뉜다. 멀티모달 표현으로 학습한 부류가 역시 뛰어났으며, 그 중에서도 GMU의 성능이 좋았다. 개인적으로 linear sum 같이 단순한 fusion 방법도 성능이 뛰어났다는 점이 놀랍다. 텍스드 모달리티의 경우 역시 사전학습된 word2vec을 학습한 MLP가 성능이 좋았다. RNN을 처음부터 학습시킨 모델이 가장 성능이 낮았다. 저자들은 RNN이 단어 간의 의미있는 관계를 파악하기 위한 충분한 양의 데이터가 제공되지 못 했기 때문이라고 추정한다.

장르 $F_{1}^{marco}$ 값을 봤을 때, 애니메이션의 경우 포스터가 텍스트보다 장르가 애니메이션이라는 것을 훨씬 쉽게 드러낸다는 사실을 알 수 있다.
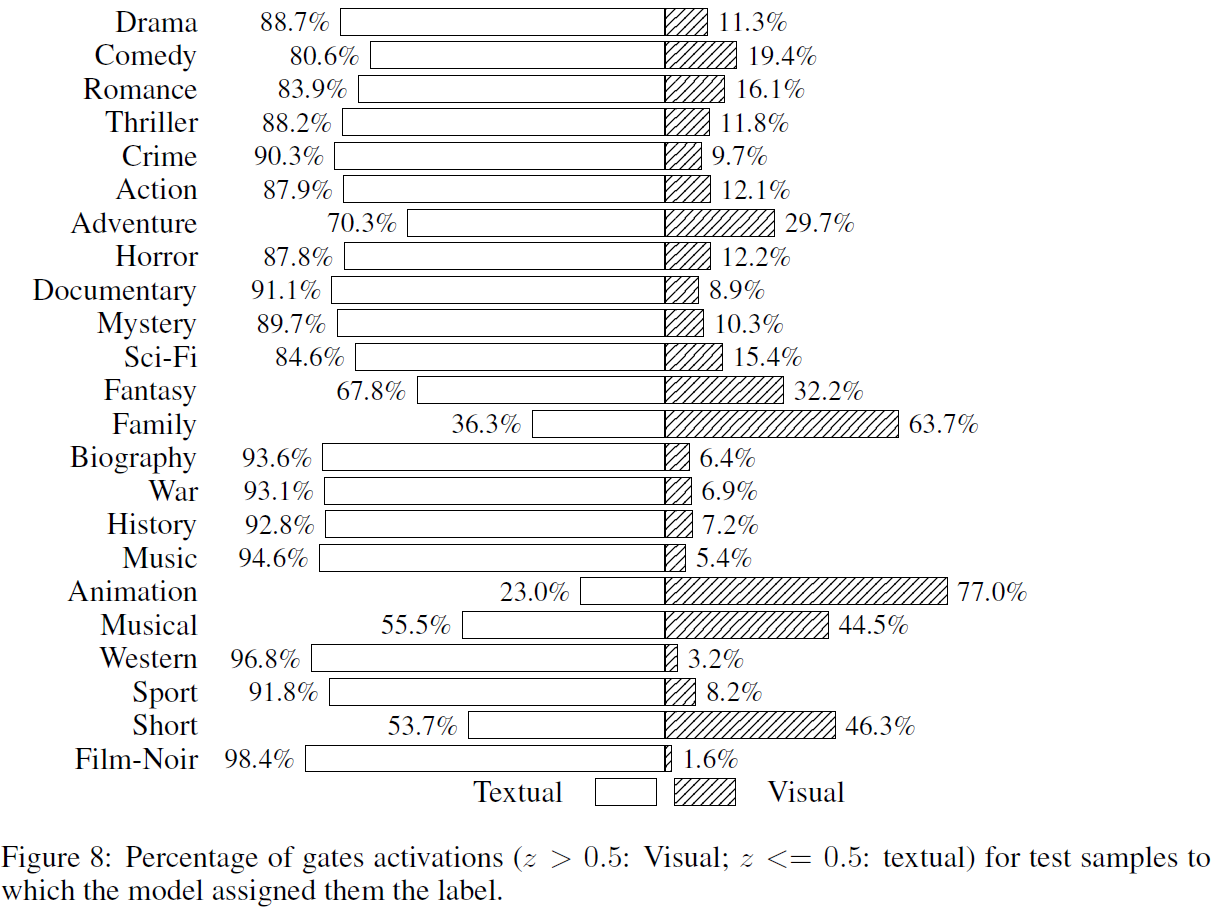
장르 별로 GMU 게이트의 활성화 값을 확인했다. 예측대로 대부분의 장르에선 텍스트 모달리티에 더 초점을 두지만, 앞서 봤던 애니메이션의 경우 포스터에 크게 집중하고 있다.

GMU가 유니모달만 썼을 때보다 상대적으로 성능을 크게 향상한 몇몇 샘플을 살펴봤을 때, 각 유니모달 모델이 예측한 레이블 중 $TP$만 골라오고, $FP$는 버린 것을 확인할 수 있다.