
티스토리 뷰
핵심 내용만 요약했다.
Section 3. Transformers
이 섹션은 바닐라 트랜스포머, ViT, 멀티모달 트랜스포머에 대해 설명한다.
셀프 어텐션은 topological geometry space 상에서 fully-connected graph로 모델링 될 수 있다. 그에 반해 CNN은 정해진 grid space 에서만 align 되도록 제약된다(다른 딥러닝 모델도 이러한 제약이 있다). 트랜스포머는 본질적으로 더 범용적이고 유연한 모델링 공간을 갖는 것이다. 그래서 트랜스포머는 복잡한 멀티모달 태스크를 풀기에 적합한 잠재력을 가졌다.
3.1 Vianilla Transformer
트랜스포머에 대해선 이미 자세히 다룬 바가 있으므로 정리하지 않았다.
하지만 한 가지 짚고 넘어가야 할 쟁점이 있다. 여러 딥러닝 모델 및 트랜스포머에선 normalization (batch, layer)을 사용한다. 그런데 post-normalization을 적용한 모델도 있고, pre-normalization을 적용한 모델도 있다. 트랜스포머는 post-normalization을 사용한다.
이를 수학적인 관점에서 바라보면, 사실 pre-normalization이 더 합리적이라는 해석이 도출된다. 이는 정규화는 프로젝션 연산 전에 수행돼야 한다는 행렬 이론 (예 : Gram-Schmidt process)의 기본 원리와 비슷하다. 그러나 아직까지 더 깊은 이론적인 연구와 실험적인 검증이 필요한 쟁점이다.
3.3.2 Self-Attention Variants in Multimodal Context
cross-modal interactions (e.g., fusion, alignment)를 위한 self-attention variants를 소개한다. formulation의 간결함을 위해 모달리티 2개를 가정하고 설명한다. 하지만 앞으로 소개 할 모든 variants들은 모달리티가 몇 개인지에 상관없이 cross-modal interaction을 위해 사용 가능하다.
$X_{A}, X_{B}$를 각 모달리티의 raw inputs tokens, $Z_{(A)}, Z_{(B)}$를 그들의 token embeddings 으로 표시하자. 그리고 multi-modal intercation 후 도출된 토큰 임베딩을 $Z$라고 표현하자. $Tf(\cdot)$은 트랜스포머 레이어/블럭을 나타내는 기호이다.
(1) Early Summation

모든 모달리티의 토큰 임베딩을 element-wise 하게 더하고, 트랜스포머의 입력으로 준다. computational complexity를 증가시키지 않는다는 장점이 있지만, weight $\alpha$를 손수 조정해야 한다는 단점이 있다.
참고로, 토큰 임베딩에 포지셔널 임베딩을 element-wise 하게 더하는 것도 early summation이다. 논문엔 언급되지 않은 내용이지만, CMU Multimodal Machine Learning 강의에선 두 임베딩의 각 position이 의미적으로 같은 공간이어야 element-wise의 결과가 의미를 갖는다고 언급한다. 즉, 무조건 더한다고 해서 정보가 fused 된 임베딩을 얻는 것이 아니다.
(2) Early Concatenation
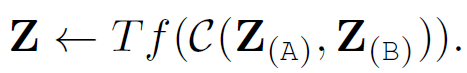
모든 모달리티의 토큰 임베딩을 그냥 이어붙여 하나의 sequence로 만든 후, 트랜스포머의 입력으로 준다. 토큰의 개수가 늘어나므로 computational complexity를 증가시킨다. 각 모달리티의 토큰은 다른 모달리티의 토큰에서 정보를 얻어 올 수 있으므로 context를 더 잘 고려한 인코딩을 할 수 있게 된다.
Early concatenation은 "all-attention" 또는 "Co-Transformer" 라고도 불린다.
(3) Hierarchical Attention (multi-stream to one-stream)
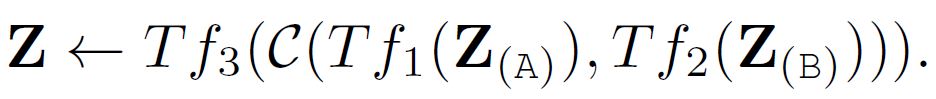
각 모달리티를 위한 트래스포머가 따로 존재하여, 일단 그것들로 토큰 임베딩을 인코딩한다. 그 결과를 모두 이어붙여서 multimodal-interaction을 위한 트랜스포머의 입력으로 준다. 이러한 hierarchical attention을 late interaction/fusion 이라고 부른다.
(4) Hierarchical Attention (one-stream to multi-stream)

multimodal-interaction을 먼저하여 얻은 임베딩을 각 모달리티를 위한 트랜스포머의 입력으로 주는 방식이다. 이 방법은 cross-modal interactions을 인식하는 와중에 각 모달리티 표현의 독립성을 보존한다.