
티스토리 뷰
[ICML 2022] Multi-Grained Vision Language Pre-Training : Aligning Texts with Visual Concepts (X-VLM)
금복이 2024. 3. 31. 13:59Introduction
VLP 모델을 학습하는 방법은 fine-grained와 coarse-grained 라는 관점으로 구분될 수 있다. 두 방식 모두 한계가 존재한다.
- fine-grained approach : pre-trained object detector로 이미지에서 객체를 뽑아낸다. 이렇게하면 객체 간의 관계를 잘 표현할 수 없게된다. 예를들어, "man crossing the street"는 "man"과 "street"의 관계를 표현한다. object detector는 오직 "man"과 "street"에 해당하는 객체를 개별적으로 추출한다
- coarse-grained approach : ViT의 patch embedding 방식을 생각하면 된다. 이렇게 하면 vision과 language 간의 fine-grained alignment를 효과적으로 배울 수 없다는 단점이 있다. 앞으로 설명하겠지만, 이러한 fine-grained alignment를 잘 배우는 것이 visual reasoning, visual grounding, image captioning 등의 다운스트림 태스크를 잘 하는데 매우 중요하다
이러한 전통적인 두 가지 접근법과 달리, X-VLM은 multi-grained version of VLP라는 새로운 카테고리에 속한다.

(a) fine-grained, (b) coarse-grained, (c) multi-grained 방식의 VLP 모델이다. 이 예제에 이용된 원본 (이미지, 텍스트) 데이터를 관찰해보자. 사실 이미지에는 여러 상황이 존재할 수 있다. 예를들어, "가방을 매고 있는 남자"라는 관계, "길을 건너고 있는 남자"라는 관계 등이 한 이미지에 담겨있다. 그러나 X-VLM이 나오기 전까지, 이렇게 이미지에 annotated 된 여러 visual concept을 학습에 활용한 모델이 부재했다. X-VLM은 visual concept을 image/region/object의 세 가지 카테고리로 분류한다.
- (image, "a man wearing a backpack is...")가 image에 대한 학습 데이터이다
- (red bbox, "man crossing the street")가 region에 대한 학습 데이터이다 (즉, 주로 객체 간의 관계에 대한 concept)
- (yellow bbox, "silver backpack")가 object에 대한 학습 데이터이다 (즉, 하나의 객체에 대한 concept)
이렇게 visual concept을 multi-grained level로 구분한 후, X-VLM은 아래와 같은 pre-training tasks를 수행한다
- Visual concept에 해당하는 텍스트와 전체 이미지가 주어졌을 때, X-VLM은 전체 이미지에서 주어진 텍스트에 대응하는 bbox를 그려야 한다 (bbox regression)
- Visual concept 간의 alignment를 배운다 (contrastive learning for each multi-grained level of concept)
Method
1. Overview
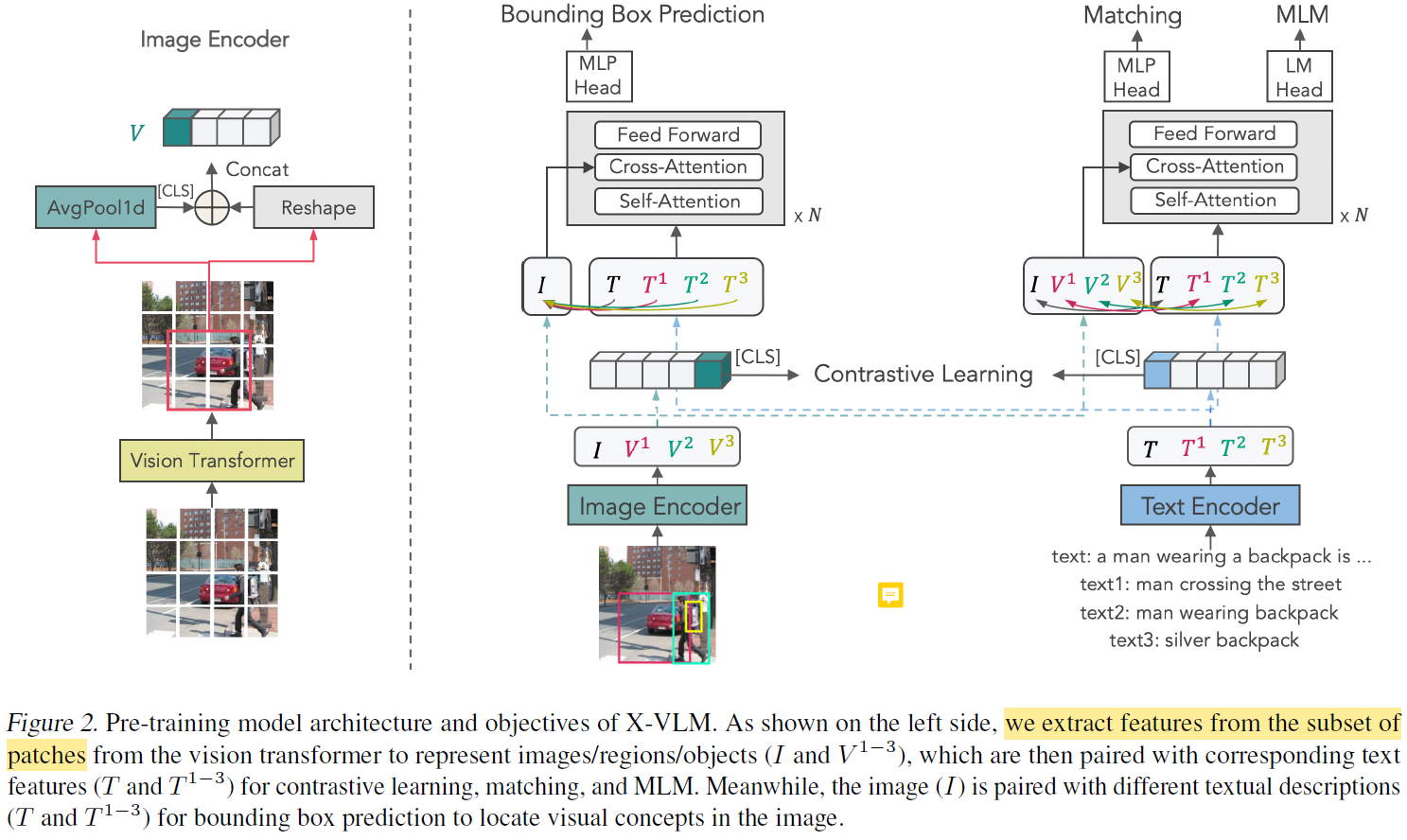
X-VLM은 image encoder ($I_{trans}$), text encoder($T_{trans}$), cross-model encoder($X_{trans}$)로 구성된다. 모든 인코더는 transformer variants이다. cross-modal encoder는 이미지와 텍스트를 cross-attention을 통해 fusion한다. 이러한 multi-stream 구조는 다른 VLP 모델들도 많이 취하는 아키텍처이다.
앞서 언급했듯이, X-VLM은 하나의 (이미지, 텍스트) 데이터에 내재된 여러 concept을 모두 학습에 활용한다. 이를 위해 일반적인 VLP의 $(I, T)$와 같은 학습 데이터 포맷이 아닌, $(I, T, {(V^{j}, T^{j})}^{N})$ 포맷으로 데이터를 re-formulation 했다. 즉, 하나의 (이미지, 텍스트) 데이터에 내재된 $N$개의 concept을 명시적으로 학습에 이용한다. $N$은 데이터마다 다르고, 내재된 concept에 대한 annotation이 없을 경우 $N=0$이므로, 이 데이터에 대해선 multi-grained version 학습이 이루어질 수 없다.
실제로 concept에 대한 풍부한 annotation을 제공하는 데이터셋으로 COCO, Visual Genome이 있다. COCO는 object annotation만 제공한다. 반면 visual genome은 region annotation까지 제공한다.
2. Vision Encoding
기본적으로 ViT의 패치 임베딩 방식을 따른다. 학습 이미지의 해상도를 224x224로 설정하고, 이를 32x32 크기의 패치 단위로 나눈다. 그러므로 이미지는 49개의 패치로 나눠진다.
각 concept에 대한 visual embedding을 출력해야 한다. 이때 $V^{j}$를 $j$번째 concept이라고 하자. $V^{j}$에 대한 visual embedding은 $I_{trans}(V^{j}) = \{v^{j}_{cls}, v_{p_{1}^{j}}, ..., v_{p_{M}^{j}}\}, j \in [0, N]$으로 정의된다. 즉, 해당 concept에 포함된 패치들의 임베딩을 모아 reshaping한 벡터이다. $v^{j}_{cls}$는 모든 패치 임베딩의 평균값으로 정의된다.
특별히 $I_{trans}(V^{0})$은 이미지에 대한 visual embedding으로 정의된다. 즉, 이미지의 모든 패치로 구성된다.
3. Cross-Modal Modeling
3.1 Bounding Box Prediction
$\hat{b}^{j}(I, T^{j}) = sigmoid(MLP(x^{j}_{cls})) = (\hat{cx}^{j}, \hat{cy}^{j}, \hat{w}^{j}, \hat{h}^{j})$
이때 $x^{j}_{cls}$는 $(I, T^{j})$를 입력으로 받은 cross-modal encoder가 출력한 $[cls]$ 토큰의 임베딩이다.
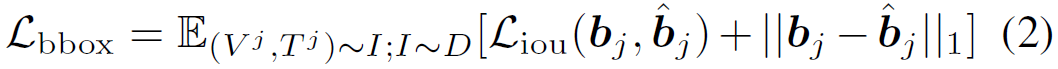
loss는 predicted bbox와 ground-truth bbox와의 l1 loss를 사용하는 것이 합리적인데, 이렇게만 하면 두 bbox간의 상대적인 에러가 비슷함에도, bbox의 크기에 따라 l1 loss의 값의 스케일이 달라지는 문제가 있다고 한다.
예를들어, 크기가 매우 큰 객체에 대한 bbox를 예측한다고 하자. 또한, 크기가 매우 작은 객체에 대한 bbox를 예측한다고 하자. 크기가 매우 작은 bbox의 경우, 두 bbox가 조금만 다르더라도 두 bbox의 IoU 값은 훅훅 떨어진다. 그러나 bbox가 크면, 두 bbox가 많이 다르더라도 IoU 값에 미치는 영향은 상대적으로 작다.
즉, bbox의 크기가 작은 concept는 좀 더 정밀하게 bbox를 예측해야 하는 것이다. 이를 고려하기 위해 두 bbox의 IoU 값을 bounding box prediction loss에 반영해줌으로써 scale-invariant한 bbox loss를 디자인한 것이다.
3.2 Contrastive Learning
여타 다른 VLP 모델의 contrastive learning과 동일하지만, 대상이 concept이라는 점이 다르다. 예를들어, ALBEF는 이미지와 텍스트를 대상으로 대조 학습을 한다. 이와 달리, X-VLM은 더 fine-grained한 concept도 대조 학습의 대상으로 삼는다.
$s(V, T) = g_{v}(v_{cls})^{T} g_{w}(w_{cls})$를 학습하고,
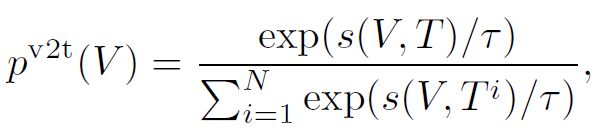
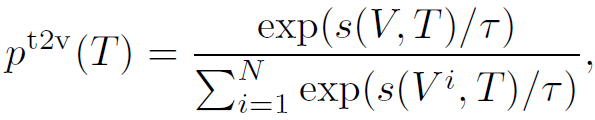
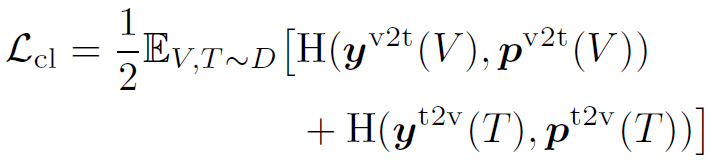
로 대조 학습을 한다. 이때 negative sample은 in-batch에서 랜덤하게 샘플링한다. 한 가지 주목할 점은, momentum model을 사용하지 않는다. 사용했다면 X-VLM의 성능이 더욱 개선되었을 텐데, 왜 도입하지 않았는지는 의문이다. 오직 multi-grained 방법이 성능 개선에 미치는 영향을 측정하려고 그랬을 수도 있다.
3.3 Matching Prediction
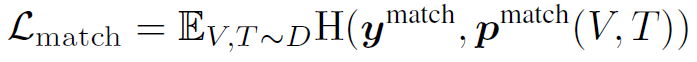
Cross-modal encoder에 매칭되지 않는 visual concept과 text 쌍, 매칭되는 쌍을 주고 매칭 여부를 예측하도록 한다. 이 또한 전형인 형태에서 벗어나지 않는다. non-mathcing visual concept / text는 $p^{v2t}(V), p^{t2v}(T)$로 샘플링한다. 즉, hard-negative sample을 뽑는다.
3.4 Masked Language Modeling
텍스트에서 25% 비율에 해당하는 토큰을 고른다. 그 후 각 토큰에 대해 10% 확률로 랜덤한 다른 토큰으로 바꾸고, 또 다른 10%의 확률로 그냥 놔두고, 80% 확률로 [mask] 토큰으로 바꾼다. 각 토큰에 대한 cross-modal encoder의 출력 임베딩에 선형 변환을 취하고 softmax 값을 뽑아낸다.


모든 loss를 더하면, X-VLM의 최종 loss가 된다.
Experiment
1. Pre-training Datasets
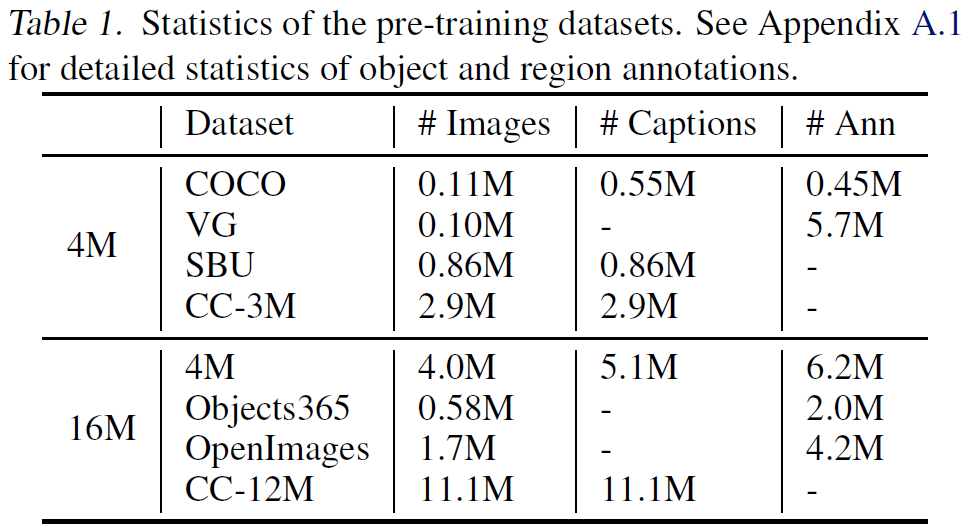
많은 VLP 모델은 4M 데이터셋을 기준으로 학습된다. X-VLM도 기존 연구들의 방식을 따른다. 앞서 언급했듯이, object annotation은 COCO와 Visual Genome, region annotation은 visual genome 데이터셋에서만 얻을 수 있다.
사전 학습 이후 다양한 다운스트림 태스크에 파인튜닝되는데, 많은 다운스트램 태스크가 COCO와 visual genome 데이터셋에 기반하고 있다. 그래서 저자들은 이러한 다운스트림 태스크들의 validation과 test 데이터셋에 포함 된 COCO 및 visual genome 데이터를 X-VLM의 사전 학습 데이터에서 제거함으로써 information leakage를 방지했다고 한다.
2. Implimentation Details
X-VLM의 image encoder로 Swin Transformer base 모델을, text encoder와 cross-modal encoder로 각각 BERT base의 앞 6-layers, 뒤 6-layers를 사용했다. 이렇게 하면 X-VLM는 총 215.6M 개의 파라미터를 갖는다.
사전 학습시 이미지는 224x224 해상도로 입력받고, 텍스트의 최대 토큰 개수는 30이다. 파인튜닝 시에 이미지 크기는 384x384 크기로 입력받고, 각 패치에 대한 positional embedding은 ViT 논문이 사용한 방법대로 보간한다.
사전 학습 때는 mixed precision 방법을 사용한다. 4M 세팅에 대해, 배치 사이즈 1024로 200K steps를 돌린다. 8대의 A100으로 학습을 했는데 총 3.5일이 걸렸다고 한다. 또한, 각 배치에서 절반에 해당하는 데이터가 bbox annotation를 포함하도록 샘플링을 했다고 한다.
AdamW optimzer with a weight deacy of 0.02. The learning rate is warmed-up to $1e^{-4}$ from $1e^{-5}$ in the first 2500 steps and decayed to $1e^{-5}$ following a linear schedule.
3. Downstream Tasks
5개의 다운스트림 태스크에 대해 X-VLM의 성능을 평가했다. 앞서 언급했듯이, 다운스트림 태스크에서의 information leakage를 방지하기 위해 COCO, Visual Genome의 일부 데이터는 사전학습에 이용하지 않았음을 다시 한 번 언급한다. 이러한 데이터가 얼마나 되는지는 모르겠지만, 일단 기존 모델들보다 학습 데이터를 조금이나마 적게 썼다는 것을 명시하고 싶은 것 같다.
- Image-Text Retrieval, Text-Image Retrieval :MSCOCO, Filckr30K 데이터셋으로 파인튜닝을 했다. 널리 이용되는 Karpathy split을 적용했다. contrastive learning loss와 image text matching loss에 대해 10 epoch 파인튜닝을 했다. 추론 과정에선, 일단 모든 이미지와 텍스트 간의 $s(I, T)$를 계산한다. 그 중에서 top-k 후보만 뽑아서 $p^{match}(I, T)$를 계산하고 최종 랭킹을 구한다. ALBEF를 따라서, MSCOCO에선 $k=128$, Filckr30K에선 $k=256$을 적용했다
- Visual Question Answering : 이미지, 이미지에 대한 질문(텍스트)가 주어졌을 때, 정답을 예측하는 다운스트림 태스스크이고, VQA 자체가 데이터셋인 것 같다. "Unifying vision-andlanguage tasks via text generation, ICML 2021" 선행 연구를 따라, six-layer Transformer decoder를 사용하여 정답을 생성(generate)한다. 디코더의 입력값은 cross-modal encoder의 최종 출력값이라고 한다. 10 epoch로 파인튜닝 했다. 추론 과정에서, 디코더가 오직 3129개의 candidate answer만 출력 할 수 있도록 제한했다고 한다(fair comparison with existing methods)
- Natural Language for Visual Reasoning (NLVR2) : 두 장의 이미지와 텍스트가 주어질 때, 해당 텍스트가 두 이미지 간의 관계를 알맞게 서술하고 있는지 판단하는 태스크이다. ALBEF를 따라, 일단 cross-modal encoder가 두 이미지에 대해서 reasoning이 가능하도록 모델을 확장한다. 그리고 4M 이미지에 대해, 두 장의 이미지와 텍스트를 모델에게 입력하고 텍스트를 첫 번째 이미지 / 두 번째 이미지 / 선택 안 함 옵션 중 하나를 결정하도록 하는 추가적인 1 epoch 사전학습을 진행한다. 이렇게 얻은 pre-trained X-VLM에 NLVR2 데이터셋을 10 epochs로 파인튜닝했다
- Visual Grounding : RefCOCO+ 데이터셋으로 파인튜닝했다. 이미지와 텍스트(description)을 주었을 때, 이미지에서 텍스트에 해당하는 부분을 locating하는 태스크이다. 이전 연구들은 이 문제를 pre-trained object detector가 제공하는 region proposals에 랭킹을 매겨서 해결했다. 이와 달리, X-VLM은 사실상 사전 학습 동안 visual grounding을 이미 배웠다. 또한, ALBEF와 같이 weakly-supervised visual grounding에 대해서도 X-VLM을 평가한다. 즉, visual grounding 데이터셋에서 grounding annotation을 학습에 사용하지 않고, 오직 이미지-텍스트 쌍만 가지고 contrastive learning loss, image-text matching loss 로만 학습을 한다
- Image Captioning : 이미지에 대한 캡션을 생성(generate)하는 태스크이다. COCO Captioning 데이터셋으로 평가를 진행한다. Karparthy test split에 대한 BLEU-4, CIDEr 스코어를 매겼다. To apply X-VLM for captioning, we do not need to add a decoder. Instead, we simply adapt X-VLM to a multi-modal decoder. Specifically, we train X-VLM with language modeling loss for one epoch on 4M data. 사전 학습할 때 이렇게 하고, COCO captioning 데이터셋으로 파인튜닝을 했다고 한다
4. Result on Retrieval
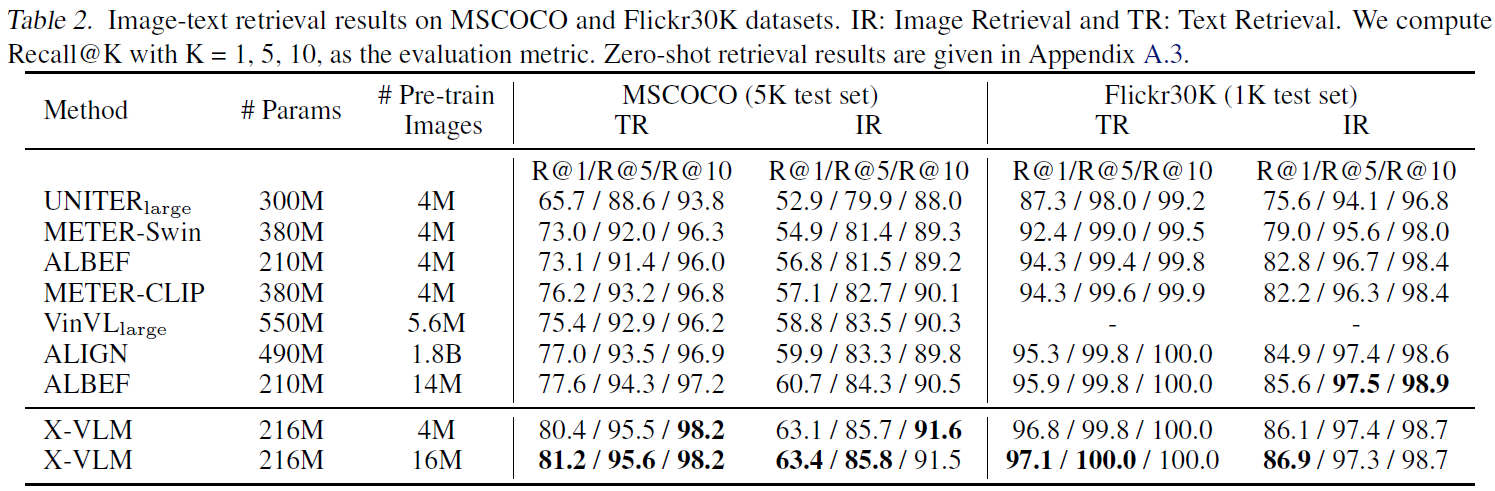
X-VLM이 SOTA를 달성했다는 것 빼고는 딱히 Table 2에서 얻을 교훈은 없다. 여담으로, METER 논문에서 VLP를 위해선 vision backbone (or parameter initialization)이 성능 향상에 중요하다는 것을 경험적으로 보였다. 그래서 swin-transformer에서 CLIP-ViT로 vision backbone을 교체함으로써 retrieval과 VQA에서 상당한 성능 향상을 이루어냈다고 한다.
5. Result on Visual Reasoning
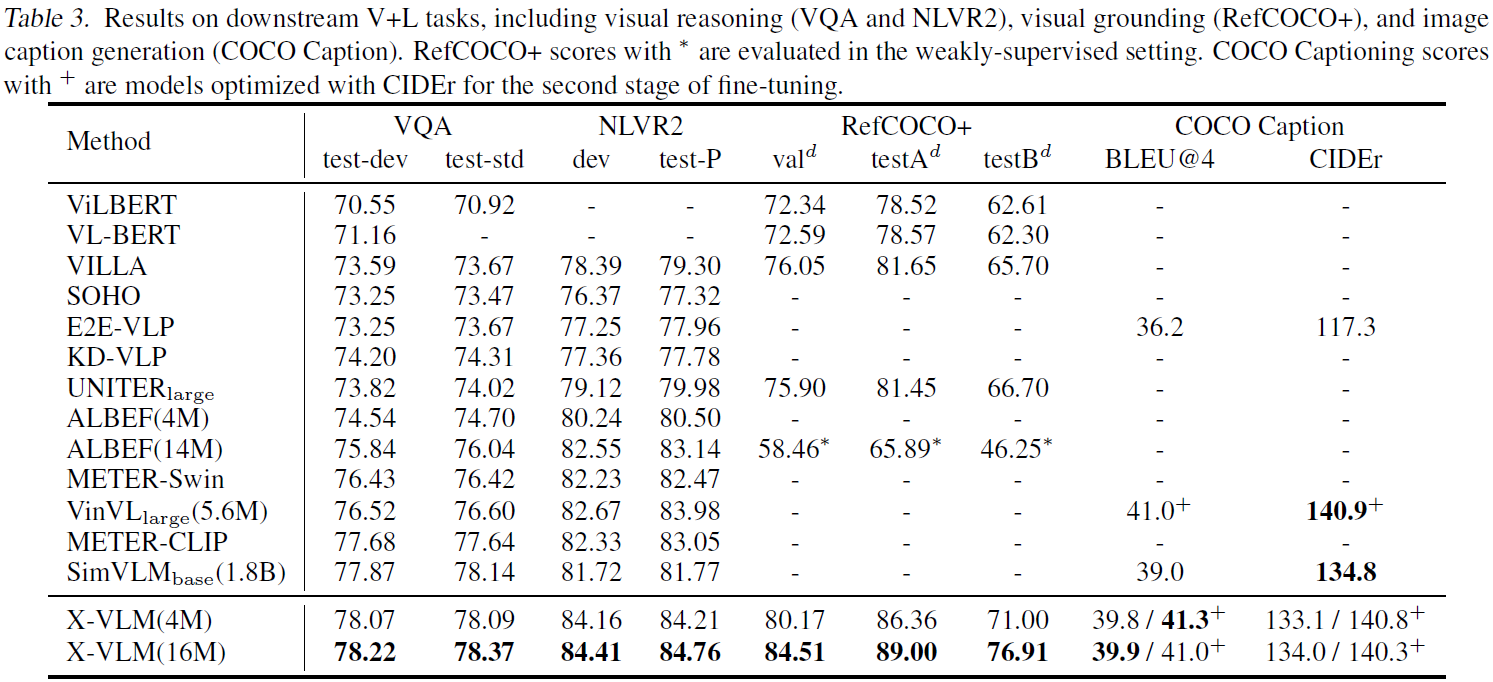
논문에선 VQA, NLVR2를 visual reasoning task라고 칭한다. Table 3에서 한 가지 관찰이 가능하다. 대표적인 coarse-grained 모델인 SOHO, METER-Swin, ALBEF 모델이 VinVL 보다 visual reasoning task에서 성능이 낮다. 심지어 ALBEF (16M) 모델은 retrieval 에선 VinVL보다 좋은 성능을 냈다. 저자들이 이렇게 말하는 것을 보아, VinVL은 fine-grined 모델인 것을 알 수 있다. 어쨌든 저자들은 visual reasoning task에서 좋은 성능을 내려면 fine-grained alignment를 잘 배웠어야 한다는 걸 말하고 싶은 게 아닐까싶다.
Visual grounding에 대한 결과는 따로 적지는 않겠다. 이미 사전학습 때 배운 것이므로, 사실 파인튜닝 자체도 안해도 된다고 생각한다.
Image captioning에서 SOTA를 달성하지 못했지만, 기존 SOTA에 비해 학습 데이터 수가 훨씬 적음에도 비견할만한 성능을 달성했다고 언급한다.
6. Ablation Study

궁금할만한 부분에 대해 ablation study를 해줘서 좋았다. 4개의 모델은 모두 4M 이미지로 80K steps으로 학습되었다. 모든 지표를 더한 Meta-Sum의 관점에서 보면, region concept을 배우는 것이 object concept을 배우는 것보다 더 중요하다고 해석할 수 있다. 또한, bounding box loss가 성능 향상에 매우 큰 역할을 하고 있음을 알 수 있다.