
티스토리 뷰
Data Efficient Masked Language Modeling for Vision and Language (EMNLP 2021)
금복이 2024. 3. 22. 14:381. Introduction
VLP의 MLM을 위한 마스킹 전략은 BERT의 마스킹 전략과 같다. 즉, 그냥 단어 토큰 중 랜덤으로 15%를 마스킹한다. 그러나 VLP에선 텍스트 뿐만 아니라 이미지도 고려할 수 있다. 즉, 이미지에서 정보를 얻어옴으로써 마스킹 된 단어가 원래 무슨 토큰이었는 지에 대한 모호함을 해소할 수 있다.

Figure 1
예를 들어 Figure 1에서 마스킹 된 단어를 텍스트만 보고 맞춰보자. 당근을 먹을 수 있는 대상은 너무나 많기 때문에, 마스킹 되기 전에 어떤 단어였는지 알기가 매우 모호하다(e.g., 사람, 토끼, 호랑이, 기린). 하지만 문장과 매칭되는 이미지에는 호랑이가 존재한다. 이 정보를 가져옴으로써 모호함이 해소된다.
본 연구는 VLP MLM에서 BERT와 똑같은 마스킹 전략을 쓰는것이 sub-optimal 라고 명시한다. 이렇게 마스킹하면 학습 데이터를 효과적으로 이용하지 못 하기 때문이다.
2. Limitations of MLM Approaches for Vision and Language
1) In many cases, no token is masked :
VLP 데이터에 있는 텍스트는 BERT를 학습 한 텍스트보다 훨씬 짧은 길이를 갖는다. 왜냐하면 이미지를 설명하는 짧은 캡션이기 때문이다. 그래서 이 문장 중 15%의 토큰을 마스킹하면, 실제로 아무 토큰도 마스킹되지 않을 수 있다. 예를들어 캡션이 6개의 토큰으로 구성되어 있다고 해보자. 이 중 6*0.15 < 1이기 때문에, 결과적으로 아무 토큰도 마스킹 되지 않는다.
2) Many masked words are stop-words and punctuation :
캡션 중 45~50%의 토큰은 stop-words 혹은 punctuation이다. 그래서 랜덤 마스킹을 하면 이런 토큰들이 마스킹 될 확률이 높다. 이는 모델이 MLM을 푸는 과정에서 이미지를 사용하지 않는 결과를 초래한다. 왜냐하면 이러한 종류의 토큰은 굳이 이미지를 보지 않아도, 문장 간의 관계에서 쉽게 복원되기 때문이다.
모델이 이미지에 의존하고 있는지에 대한 여부를 알기 위한 amnestic probing라는 실험이 있다. MLM 학습이 끝난 뒤에, 모델에게 텍스트만 주고 MLM을 시켜보는 것이다. 만약 모델이 이미지에 많이 의존하는 학습을 했다면, 텍스트만 줬을 때 마스킹 된 단어를 잘 복원하지 못 할 것이다. 실제로 VLP에서 BERT 방식의 마스킹 전략을 쓴 경우, amnestic probing을 했을 때 (텍스트만 줬을 때) 모델이 마스킹 된 토큰을 잘 복원하는 것을 확인했다.
저자들은 VLP 데이터셋의 이러한 특성을 반영하여, VLP를 위한 새로운 마스킹 전략을 제안한다. 복원을 위해 이미지가 요구되는 토큰 (e.g., physical objects)를 마스킹한다. 그리고 새로운 메트릭 ($\Delta $ image loss)를 도입하는데, 이는 마스킹 된 각 토큰의 복원을 위한 이미지의 필요성을 측정한다.

$\Delta $ image loss는, 모델에게 텍스트만 주고 마스킹 된 토큰을 복원시켰을 때의 loss (MLM이니까 cross-entropy loss일 것이다)와 (이미지, 텍스트)를 주고 마스킹 된 토큰을 복원시켰을 때의 loss의 차이이다. 이 값이 클수록 모델은 이미지에 의존적이다.
3. Alternative Masking Strategies
본 논문은 VLP MLM에서 랜덤 15% 마스킹보다 효과적인 마스킹 전략들을 소개한다. 제안하는 전략은 몇 가지의 semantic classes를 사용한다.
3.1 Semantic Classes
Objects, Attributes, Relationships의 세 종류가 있다.
- Objects : Physical entities in the image (e.g., a tiger, a carrot)
- Attributes : properties of objects, such as color or physical state (e.g., upright)
- relationships : connect between two objects (e.g., eating, behind)
이런 종류의 토큰을 마스킹해야 모델이 이미지에서 정보를 얻어와 복원 과정의 모호함을 해소할 수 있을 것이다. 그런데 이를 위해선, 텍스트에서 어떤 토큰이 objects, attributes, relationships에 속하는 지를 알아야한다. GAQ(Question Answering on Image Scene Graphs)와 같은 몇몇 데이터셋은 이에 관련된 annotations을 제공한다. 그래서 저자들은 해당 annotations를 ground-truth로 사용하고, 텍스트에서 o/a/r을 자동으로 찾아내는 휴리스틱 알고리즘을 만들었다고 한다.
이러한 알고리즘으로 o/a/r을 식별했다고 하면, 다양한 마스킹 전략을 디자인할 수 있다.
3.2 Proposed Strategies
저자들은 아래와 같은 마스킹 전략들을 고려한다.
- Baseline MLM : LXMERT에서 사용한 마스킹 전략. 15% 랜덤 토큰 마스킹
- Objects : 랜덤한 하나의 object word를 마스킹
- Content words : 하나의 word를 마스킹하는데, stop-words가 마스킹 될 확률은 20%이며 content word가 마스킹 될 확률은 80%
- Top concrete : Mask one of the top concrete words in the sentence, weighted by their order. 단어마다 concrete score를 매겨놓은 annotation (Brysbaert et al., 2014)을 사용했다. concrete score (범위 : 1 ~ 5)가 높을수록 추상적이지 않다는 것을 의미하며, 인간의 오감으로 직접 느낄 수 있으며 실체로서 존재한다는 것이다. concrete한 단어들을 마스킹해야 모델에게 이미지에 더 반응할 것이라는 직관에 기반한 마스킹 방법인 것이다.
- Stop-words & puncuation : 오직 stop-words/punctuation만 골라서 15% 랜덤 마스킹
- Random 1 word : 랜덤한 하나의 word를 마스킹
Tokenization : BERT tokenizer를 사용. 바로 위에 소개한 마스킹 전략 중 word-level 마스킹(Objects, Content words, Top concrete, Baseline MLM, Random 1 word)에 대해선, 마스킹 할 word에 속한 모든 pieces를 마스킹한다.
4. Experiments
4.1. Downstream Tasks
각 마스킹 전략을 평가하기 위해, 해당 마스킹 전략으로 LXMERT 모델로 VLP를 진행한 후 VQA, GOA, NLVR2 다운스트림 태스크에 파인튜닝한 성능을 비교한다. 또한, VLP 학습을 전체 학습 데이터의 10%, 20%, 50%, 100%로 구분해서 진행하여 각 마스킹 전략의 data efficiency 능력을 평가한다. VLP 학습은 총 7 epochs로 진행했다(원래 VLP는 20 epochs로 하는 게 일반적인데, 다양한 실험을 하기 위해 7 epochs 만 진행했다고 한다).
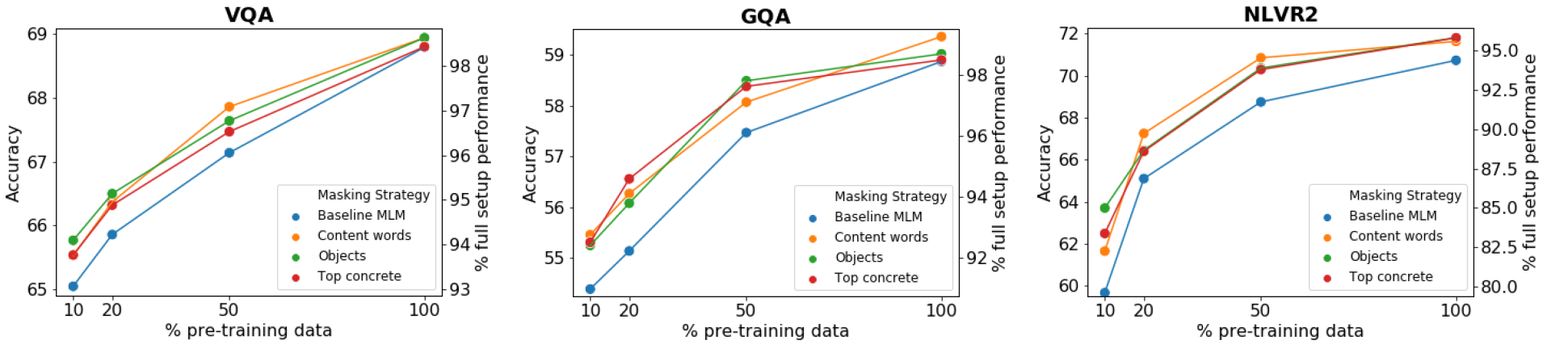
실험 결과는 위와 같다. 주목해야 할 점은, 사전 학습 데이터가 적을수록 논문이 제안한 마스킹 전략이 baseline MLM 보다 더 높은 성능을 보인다. 이러한 격차는 사전 학습 데이터가 많아질수록 줄어드는 양상을 확인할 수 있다.
Appendix B.2. How to change the 15% masking amount?
15% 마스킹 전략의 결과를 생각해보자. 전체 텍스트 데이터에서, 어떤 문장은 토큰이 7개보다 적을 것이고, 어떤 문장은 1개의 토큰만 마스킹 될 것이고, 토큰이 많은 문장은 여러 개의 토큰이 마스킹 될 것이다. 저자들은 이러한 요인을 각각 분리하여 실험을 진행해본다. 즉, 세 가지의 실험이 있다.
- Not allowing 0 masked : 어떤 문장에 대해 마스킹 할 토큰이 0개라면, 하나의 토큰을 랜덤하게 골라 마스킹한다. 어떤 문장에 대해선 multiple masked를 허용하는 것이다.
- Not allowing multiple masked : 어떤 문장에 대해 마스킹 할 토큰이 2개 이상이라면, 그 중 하나의 토큰만 골라서 마스킹한다. 어떤 문장에 대해선 0 masked를 허용하는 것이다.
- Masking only 1 word : 모든 문장에 대해, 마스킹 할 word를 고르고, 그것을 구성하는 wordpiece token을 모두 마스킹한다.

이런 세 가지 마스킹 전략으로 각각 XLMERT VLP를 진행하고 GQA, VQA, NLVR2 태스크에 파인튜닝 한 결과 성능을 비교한 테이블이다. 결과적으로 각 문장에 대해 오직 하나의 word만 마스킹하는 것이 가장 좋은 결과를 보였다. 또한 multiple masked를 금지하는 것 보다는 0 masked를 금지하는 것이 조금 더 나은 결과를 보였다.

또한, 아무 word 중 하나를 마스킹하는 전략보다는, objects인 word 중 하나를 마스킹하는 Objects 마스킹 전략이 다운스트림 태스크에 대해 더 좋은 결과를 보였다.
4.2. Prompt Based Object Detection
각각의 마스킹 전략으로 학습된 XLMERT 모델이 이미지에 대해 얼마나 reposntive 한지 평가하기 위한 실험이다. 베이스라인은 XLMERT (original paper)인데, 저자들이 제안한 마스킹 전략으로 XLMERT를 사전학습 시킬 때는 학습 데이터를 50%, epochs를 7번만 돌렸다고 한다 (original XLMERT는 20 epochs로 학습되었다).
각 모델이 이미지에 대해 얼마나 responsive 한지 평가할 수 있는 방법을 설명하겠다. 각 모델에게 (이미지, 텍스트) 데이터를 줄 껀데, 여기서 텍스트는 "A photo of a [MASK]"로 준다. 즉, 프롬프트 역할을 한다. 모델은 마스크 토큰을 복원하기 위해 이미지와 contextualizing을 수행하고, 최종적으로 vocabulary에 있는 모든 단어 토큰에 대한 softmax 값을 뱉는다. 이 값중 상위 $k$개의 confidence를 갖는 토큰만 가져와서, image ground-truth scene-graph 에 있는 ground-truth objects list와 비교하여 모델이 몇 개의 object를 맞췄는지 정확도를 구하면 된다.
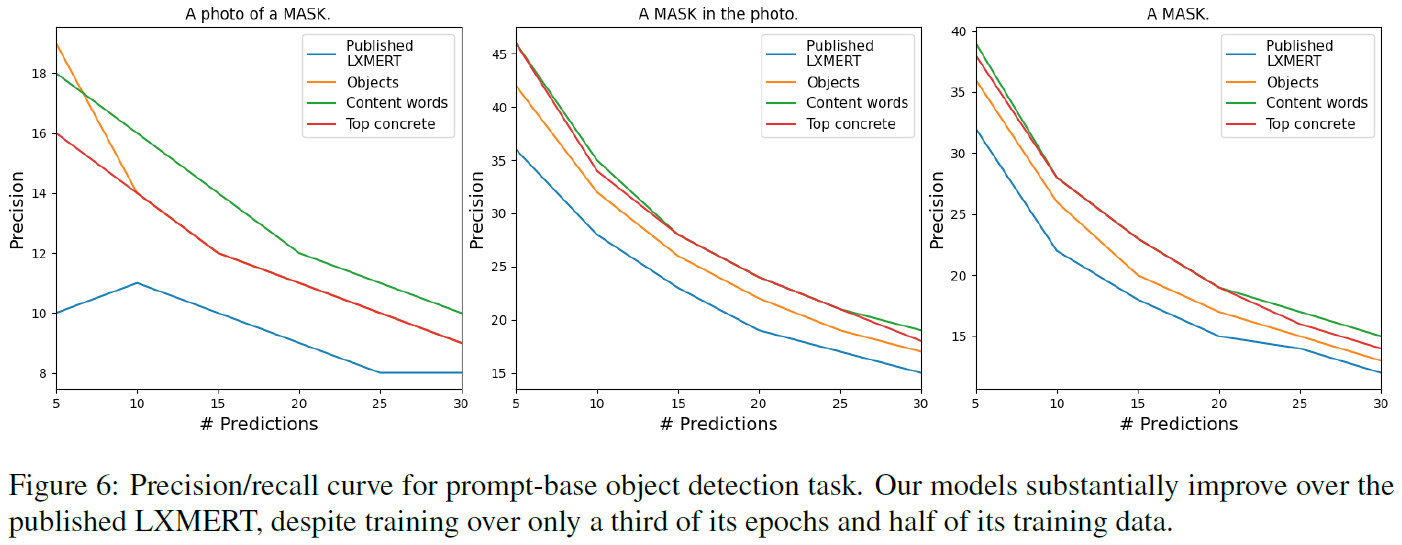
프롬프트를 약간씩 다르게 줘서, 총 3개의 프롬프트에 대한 실험을 진행했다. x축은 모델의 top-$k$ confidence 에서 $k$를 의미한다. y축인 prediction은 $k$개 중, ground-truth objects lists에도 있는 객체의 개수를 $k$로 나눈 값이다. 즉, 이 값이 높을수록 모델이 이미지에 대해 더욱 reponsive 하다고 해석할 수 있다.
Original XLMERT가 더 많은 사전 학습 데이터와 약 3배 더 많은 epochs로 학습되었음에도 불구하고, 저자들이 제안한 마스킹 전략으로 사전학습된 XLMERT 모델들이 이미지에 더 reponsive 한 것을 볼 수 있다.
뿐만 아니라 precision-recall curve를 그려봤을 때도 저자들이 제안한 마스킹 전략으로 학습된 모델이 original XLMERT 보다 더 좋은 결과를 보인다 (본 논문 appendix에 plot 있음).

Object 마스킹 전략으로 학습된 XLMERT와 original LXMERT (랜덤 15% 토큰 마스킹 전략으로 학습)의 top-$5% confidence tokens과 ground-truth objects list를 비교한 그림이다.
5. Analysis and Discussion
5.1. Hierarchy of Masked Semantic Classes
마스킹한 토큰이 모델을 이미지에 의존적으로 만드는 지를 이해하기 위한 실험을 진행한다. 이를 위해서 각 문장의 모든 토큰마다 $\Delta$ image loss 를 계산한다. 모델은 original LXMERT (fully pre-trained)를 썼으며, 문장은 original LXMERT의 validation dataset을 사용했다. 참고로 추출된 $\Delta$ image loss는 깃허브에 공개되어 있다.
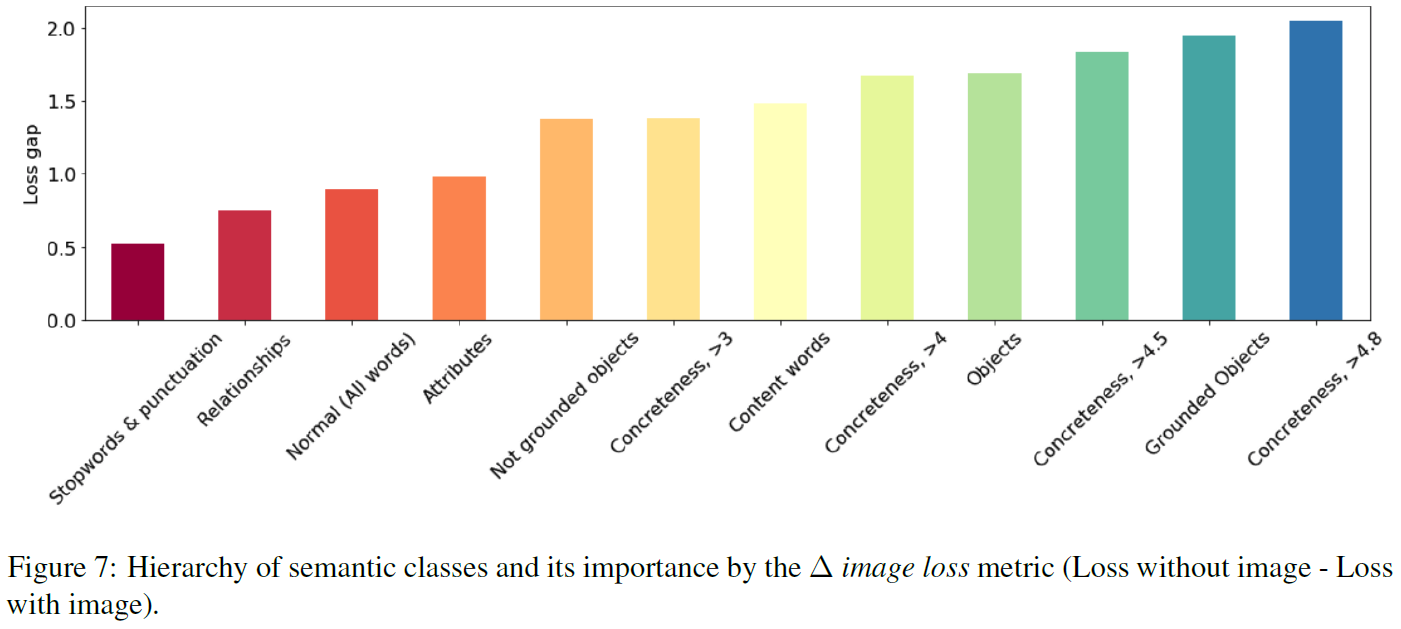
다양한 semantic classes에 대한 $\Delta$ image loss를 정렬한 plot이다. 몇 가지의 관찰을 할 수가 있다. 첫 번째로, 텍스트에도 존재하고, 이미지에도 존재하는 objects word (e.g., 맨 처음 plot의 "tiger")가, 이미지에는 존재하지 않는 objects word보다 더 중요 (loss gap이 더 큼)하다는 관찰이다.
두 번째로, objects word가 가장 중요한 semantic class라는 것이다. 이는 저자들이 제안한 마스킹 전략들에 대한 다운스트림 태스크 성능 지표의 결과와 일맥상통하는 중요한 부분이다. 왜냐하면 다운스트림 태스크 성능에서도 stop-word & puncuation만 마스킹하는 전략이 가장 낮았으며 (Figure 7에서 loss gap이 가장 낮음), objects와 top concrete를 마스킹하는 전략이 가장 높았기 때문 (Figure 7에서 loss gap이 가장 큼)이다.
즉, $\Delta$ image loss가 큰 semantic class의 word를 마스킹하는 것이, 다운스트림 태스크에서의 성능에 가장 좋은 영향을 끼친다.
5.2. MLM Performance across Word Classes
이전의 많은 연구들은 VLP 모델이 모든 토큰을 (마스킹 했을 때) 잘 복원할 수 있는 능력을 가져야 한다고 가정한다. 즉, objects, properties, stop words, punctuation 등의 모든 semantic class에 대한 토큰을 모두 잘 복원해야 한다는 것이다.
저자들이 제안한 objects 마스킹 전략은 오직 objects word만 마스킹한다. 이런 전략으로 VLP를 진행하면, 모델은 다른 종류의 semantic class 토큰도 잘 복원해낼 수 있을까? 만약 복원을 잘 못한다면, 이러한 마스킹 전략은 효과적이라고 할 수 있을까?
이를 실험하기 위해, 각 마스킹 전략으로 사전 학습된 모델 (학습 데이터의 50%로만 학습했다)을 준비한다. 그리고 그 모델들에게 다양한 마스킹 전략으로 마스킹 한 문장을 주고, 마스킹 된 토큰을 복원하도록 해본다. 이렇게 하면 사전 학습 과정에서 마스킹 되지 않은 semantic class 토큰에 대한 복원 능력을 측정할 수 있다.

실험 결과를 보자. Objects 마스킹 전략을 적용한 모델은 stop-words, punctuation, relationships 에 속하는 토큰들을 잘 복원하지 못했다. 중요한 점은, 그럼에도 불구하고 다운스트림 태스크 파인튜닝에 대한 성능 (사실 이 지표가 가장 중요하다)은 Baseline MLM (15% 랜덤 마스킹) 보다 좋았다는 것이다.
이는 모델이 모든 종류의 semantic class 토큰을 잘 복원하는 능력을 굳이 가지지 않아도 됨을 시사한다. 특정 semantic class (e.g., objects)가 다른 것들보다 모델에게 훨씬 다운스트림 태스크에 대한 추론 능력을 기르는데 도움이 될 수 있다.
그런데 한 가지 생각해봐야 할 포인트가 있다. 저자들이 고려한 다운스트림 태스크들은 전부 imge-text 간의 retrieval 능력을 주로 요구하는 태스크들이다. 즉, objects 마스킹 전략으로 학습한 모델은 retrievel 과는 사뭇 다른 역량을 요구하는 태스크는 잘 못 풀 수 있다. 실제로도 그런 결과가 나오는지 실험을 진행했다.
Objects 마스킹 전략으로 학습된 모델에게 attributes, relations과 관련된 질의를 하는 것이다.

실험 결과가 매우 놀랍다. Objects 마스킹 전략은 Baseline MLM 전략보다 attributes, relations 관련 질의에 대해 더 높은 성능 지표를 기록했다. attributes, relations에 속하는 토큰을 복원하는 일은 잘 못하지만, 그와 관련된 다운스트림 태스트는 잘 푸는 것이다.
6. Related Work
6.3 Challenges in VQA generalization
- Visual understanding : VLP 태스크는 내재적으로 이미지와 텍스트 둘 다에 대한 깊은 이해를 요구한다. 하지만, 지금까지의 많은 연구들은 모델이 strong language priors (e.g., superficial cues)에 의존하여 VQA 태스크에서 성공을 거뒀음을 보인다. 즉, 모델은 이미지에 대한 이해 능력이 다소 부족할 수 있다. 몇몇 연구는 모델이 옳은 이미지 영역을 보도록 권장하는 방법을 제안하기도 했다.
- Bias : Yang et al. (2021), Hendricks et al. (2018)은 어텐션 기반의 VLP 모델이 어텐션 모듈이 학습 데이터의 spurious correlations에 집중하도록 유도하는 bias 때문에 좋지 않은 일반화 능력을 가지게 됨을 보였다. 아래의 Figure 9가 그러한 예시를 보여준다. 사전학습 동안 모델이 이미지에 더 집중하도록 하는 것이 이러한 language priors bias를 완화하는 데 도움이 될 수 있다.

Appendix
A.1 Detection of Objects, Attributes and Relationships
- Using the annotated scene-graph as ground turth : 텍스트에서 objects, attributes, relationships를 식별하는 가장 간단한 방법이다. Visual-Genome, GOA와 같은 데이터셋은 이미지에 담긴 객체에 대한 scene-graph annotation을 제공한다.
- Predicting : scene-graph가 없는 경우에는 어떻게 식별할 수 있을까? Part-of-speech tagging (POS)를 이용할 수 있다. 예를들어, 어떤 텍스트의 어떤 단어의 POS가 "NOUN"이고, 그 단어가 visual genome objects list에 있으면 objects로 취급하는 것이다.
Table 5

다운스트림 태스크 파인튜닝 성능이 좋은 마스킹 전략일수록 training MLM loss가 상대적으로 높은 것을 알 수 있다.