
티스토리 뷰
1. Abstract
- 본 논문은 특정 단어(예 : 숫자, 알파벳)에 대한 발음(오디오 모달리티)과 입모양(비디오 모달리티)의 표현을 잘 fusion하고, fusion된 표현을 인풋으로 받는 classifier를 학습하여 발음을 구분하는 태스크를 다룬다. 이 과정에서 fusion을 잘하기 위해 오토인코더를 도입한다.
- 피처 학습시 오디오와 비디오 모달리티가 주어졌다면, 모델에게 비디오 모달리티만 줘도 상대적으로 더 좋은 표현을 만든다.
- 모달리티 간의 공유(shared)된 표현을 어떻게 배우는지 보여준다. 이를 평가하기 위해 classifier를 오디오 모달리티로 학습시키고 테스트는 비디오 모달리티로 하거나, 그 반대로 실험을 한다.
2. Introduction

오디오, 비디오 표현을 fusion하여 발음을 구분하는 태스크는 총 세 단계로 구분된다. 1. feature learning, 2. supervised training, 3. testing이다. supervised training에선 linear classifier를 썼다. testing은 서로 다른 feature learning 방법의 성능을 비교하는 단계이다. 여기서 비교하는 feature learning은 총 3개이다. multimodal fusion, cross modality learning, shared representation learning이다.
Supervised training에서, classifer는 오토인코더가 생성한 피처(representation)을 인풋으로 받아 발음 분류를 수행한다. Figure1에서 Class Deep Learning은 unimodal일 때를 의미한다.
- Multimodal Fusion 방법에선 태스크의 세 단계에서 모두 멀티모달이 주어진다.
- Cross Modality Learning은 피처 러닝 단계에서 오디오와 비디오 모달리티가 주어졌다면, 오토인코더에 비디오 모달리티만 넣어도 좋은 표현이 만들어지는 지를 보려는 목적으로 도입됐다. 즉, 피처 러닝때 비디오 모달리티만 넣고 학습한 오토인코더가 만드는 표현보다 더 좋은 표현이 만들어질까가 궁금한 것이다.
- Shared Representation Learning은 classifier을 학습할 때와 테스트 할 때 서로 다른 모달리티를 사용한다. 이는 오토인코더가 만든 표현이 두 모달리티 간의 상관관계를 잘 포착하고 있는지를 보려는 목적이다. 오토인코더가 modality-invariant한 정보를 배웠는지 확인할 수 있다.
3. Learning Architecture

논문에서 주된 피처 러너로 왜 오토인코더를 선택했는지 알아보자. 논문에선 피처 러너로서 기본적인 모델로 Restricted Boltzmann Machines (RBM)을 고려한다. Figure2의 (a), (b)는 각각 unimodal Auido RBM, Video RBM이다. 간단한 멀티모달 피처 러너는 단순히 두 모달리티의 인풋을 concat한 RBM이다. 하지만 이 RBM은 shallow한 모델로 오디오와 비디오 간의 높은 비선형성 관계를 포착하기 어렵다고 한다. 딥러닝의 아이디어를 빌려와서, 각 unimodal RBM이 만든 피처를 concat하여 인풋으로 받는 RBM을 생각해보자. 이렇게 하면 각 모달리티간의 비선형 관계를 좀 더 잘 포착하긴 할 것 같다. 하지만 deep하게 만들었다고 해서 modality-across interaction을 해 줄 것이라는 보장은 없다.

결국 오토인코더는 modality-across interation을 더 잘 시키기 위해 도입되었다. fig3의 (a)는 비디오만 인풋으로 받아 비디오와 오디오를 복원해야 하는 오토인코더이다. 만약 이 모델 안에서 modality-cross interaction이 잘 일어나지 않는다면 오디오를 잘 복원할 수 없을것이다. 즉, 오토인코더의 특징을 이용하여 modality-cross intraction을 강제하고 있다. (b)는 denoising autoencoder에서 영감을 받아 만든 모델이라고 한다. 이 모델의 학습 데이터의 1/3은 : No video(video input을 0으로 채움) + audio이고, 또 다른 1/3은 video + No audio, 마지막 1/3은 video + audio이다. 한 쪽 모달리티의 인풋을 0으로 채운 상태로 학습을 하는 건 본직적으로 (a) 모델을 학습시키는 것과 같다고 한다. 그래서 (b) 모델은 한 쪽 모달리티가 부재하더라도 적절한 표현을 만드는 robust한 모델이 될 것이라고 기대할 수 있다. 두 오토인코더는 처음에 figure2의 (d) 파라미터로 초기화된다. Video-Only Deep Autoendoer의 경우 오디오 파라미터는 필요가 없으므로 비디오 파라미터만 가져온다.
4. Experiments
4.1 Result of Cross modality learning
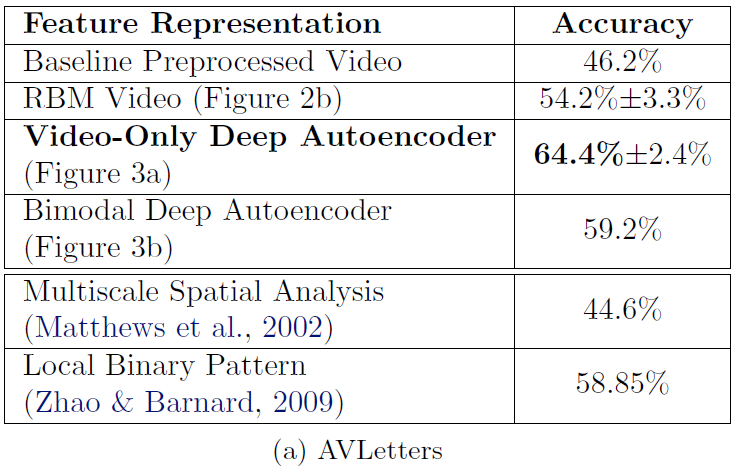

(a) AVLetters는 알파벳 발음 분류 데이터셋이고, (b) CUAVE Video는 숫자(0~9) 발음 분류 데이터셋이다. 두 가지 데이터셋에 대해, 비디오로만 classifier를 학습한 cross modality learning을 수행한 결과이다. 여기서 bimodal autoencoder가 video-only deep autoencoder 보다 accuracy가 낮다. video-only autoencoder는 오직 비디오만 인풋으로 받기 때문에, 비디오에 관련된 표현을 배운다. 하지만 그 표현은 오디오를 reconstruction하는데도 역시 좋은 것이다. 이에 반해 bimodal autoencoder는 audio-only, video-only, invariant 피처를 각각 배운다. 그래서 classifier 학습시 비디오 인풋만 주어지면 아마도 optimal이 아닌 것 같다고 저자들은 말한다.
또한 오디오로만 classifier를 학습하는 cross modality learning의 경우 unimodal audio RBM의 accuracy보다 높지 않았다고 한다. 오디오는 그 자체로 발음 분류에 매우 효과적인 모달리티여서, 피처 러닝시 비디오 모달리티의 정보를 반영하면 오히려 모델의 성능이 저하시킬 수 있다고 한다.
4.2 Result of Multimodal Fusion
바로 위에서 오디오와 비디오의 정보를 함께 이용하면 모델의 성능이 오히려 하락할 수 있다고 했다. 하지만 두 모달리티를 이용하면 더 좋아지는 상황이 있긴하다. 오디오의 음질이안 좋을때 비디오가 이를 잘 보충(complement)를 잘 해 줄 때이다. 그래서 저자들은 오디오의 음질이 좋을 때와 나쁠 때의 두 가지 케이스를 나눠서 multimodal fusion 결과를 제시한다.

오디오의 음질이 좋은 경우는 그냥 unimodal audio RBM을 쓰는 것이 가장 좋았다. 멀티모달 모델들은 비디오의 정보 때문에 오히려 성능이 하락했다. 그러나 오디오의 음질이 나쁜 경우에는 Bimodal autoencoder의 표현에 Audio RBM의 표현을 concat한 표현을 학습한 classifier의 accuracy가 다른 피처 학습 방법들을 제쳤다. 이를 통해 오디오만으로 부족한 정보를 비디오가 보충해줌을 확인했다.
4.3 McGurk effect
McGurk effect란, 사람에게 소리는 "ga"로 들려주는 동시에 입 모양은 "ba"로 보여주면 결과적으로 "da"로 인식하는 것을 말한다. 이는 사람을 대상으로 할 때 발생하는 것인데, 과연 멀티모달 표현으로 학습한 모델에서도 이런 효과가 일어날까?

bimodal deep autoencoder의 features(fig3.b)로 svm 학습시킨후, 오디오 인풋에는 "ga"를, 비디오 인풋에는 "ba"를 넣으면 McGurk effect가 발생하는지 확인할 수 있다. 그 결과는 놀라웠는데, McGurk effect가 발생했기 때문이다. 흥미로운 점은 fig2.(d) 또는 fig2.(a)와 fig2.(b)를 concat한 표현을 학습한 classifier은 효과가 발생하지 않았다.
4.4 Result of Shared Representation Learning
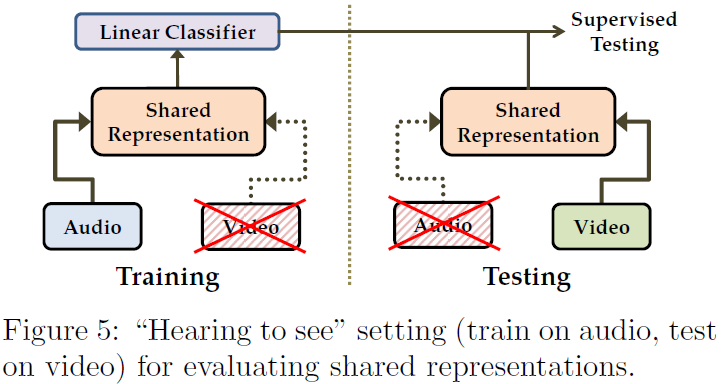
Shared Representation Learning을 그림으로 표현한 것이 Figure 5이다. 학습, 테스트 때 서로 다른 모달리티를 인풋으로 주는 것이다. 학습때는 비디오 인풋을, 테스트 때는 오디오 인풋을 넣는다면 위와 같이 "Hearing to see"를 실험하는 것이다.
Modality-invariant, 다시말해 두 모달리티가 공통적으로 가지는(shared) 표현을을 배우는 기존의 좋은 접근법은 Canonical correlation analysis(CCA)이다.
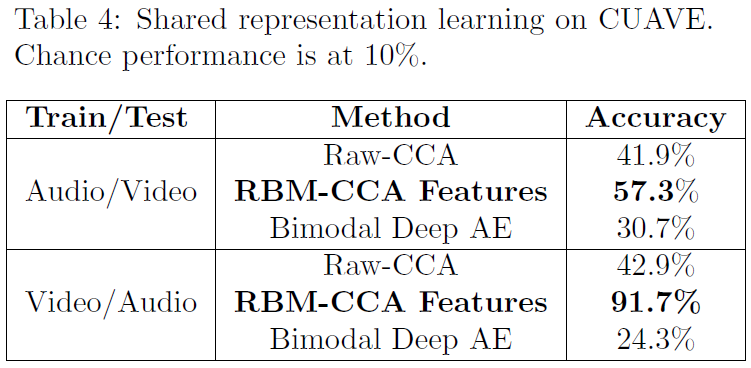
오디오/비디오의 raw input에 CCA를 적용하여 피처 학습을 했을 때가 Raw-CCA이다. 그런데 unimodal RBM가 뽑아낸 피처에 CCA를 적용하니 accuracy가 매우 많이 올랐다. 이러한 결과는 모달리티간의 관계를 포착하려면 적어도 하나의 non-linear한 연산이 있어야 함을 시사한다고 해석할 수 있다. Bimodal Deep autoencoder는 CCA에 비해 성능이 좋지 않았다(CCA는 cross-modality learning에선 성능이 좋지 않았다고 한다).
그러나 Bimodal Autoencoder의 accuracy도 무시할 정도로 낮지는 않아서, 부분적으로 모델이 배운 표현이 invariant(shared) 속성을 띄고 있다고 볼 수 있다.
4.5 Additional Control Experiments
- Video-only autoencoder에서 audio를 재구성하도록 하지 않으면(즉, 비디오만 재구성하게 하면), cross modality learning에서 두 데이터셋 각각에서 성능이 약 7.7%, 14.3%하락함.
- Video-only autoencoder에서 인코더의 깊이(depth)를 3층에서 1층으로 줄였더니 성능이 2.1%, 5.0%하락함.
- Bimodal BDN을 학습시켰을 때 cross modality learning, shared representation learning에서 성능이 나빴고, McGurk effect도 발생하지 않았음. multimodal fusion에선 autoencoder과 비교할 때 5% 정도의 성능 하락이 있었음. 즉, 오토인코더를 도입했을 때 cross-modality interaction이 더 잘 일어남을 확인함.