
티스토리 뷰
K-평균은 군집화(Clustering)에서 가장 일반적으로 사용되는 알고리즘입니다. K-평균은 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법입니다. K-평균 군집화 알고리즘의 동작 방식을 단계별로 살펴봅시다.

- 먼저 군집화의 기준이 되는 중심을 군집의 개수만큼 임의의 위치에 가져다 놓습니다. 보통 임의의 위치에 중심을 놓게되면 알고리즘이 너무 많이 반복되어 수행 시간이 오래걸리기 때문에 초기화 알고리즘으로 적합한 위치에 중심을 가져다 놓습니다.
- 각 데이터는 자신과 가장 가까운 중심점에 소속됩니다. 위 그림에서 처음에 A, B 데이터가 같은 중심점에 소속되며, C, E, F 데이터가 같은 중심점에 소속됩니다.
- 모든 데이터의 소속이 결정되면, 군집 중심점을 소속된 데이터의 평균 위치로 이동시킵니다.
- 중심점의 위치가 바뀌었으므로, 각 데이터에 대해 기존에 속한 중심점보다 더 가까운 중심점이 있다면 해당 중심점으로 소속을 변경시킵니다. 위 그림에서 중심점이 바뀐뒤 C 데이터의 소속이 변경되었습니다.
- 다시 모든 중심점의 위치를 소속 데이터의 평균 위치로 이동시킵니다.
- 중심점이 옮겨졌는데도 모든 데이터의 소속이 바뀌지 않을때까지 위 과정을 반복합니다.
K-평균 알고리즘은 군집화에서 가장 많이 활용되며, 절차가 쉽고 간결하다는 장점을 가집니다. 하지만 거리 기반 알고리즘으로 피처의 개수가 만을수록 군집화 정확도가 떨어집니다. 이 때문에 PCA로 차원을 축소하는 것을 고려할 수 있습니다. 또한 반복 수행 횟수가 많을수록 알고리즘의 수행 시간이 오래 걸리며, 총 몇 개의 군집으로 군집화를 수행해야 할 지 가이드하기가 어렵다는 단점이 있습니다.
사이킷런은 K-평균 알고리즘을 구현한 KMeans 클래스를 제공합니다. KMeans 클래스의 중요한 파라미터는 다음과 같습니다.
- n_clusters : 군집화할 개수
- init : 초기 군집 중심점의 좌표를 설정할 방식을 말하며, 보통 임의의 중심을 설정하지 않고 일반적으로 "k-means++" 방식을 설정합니다.
- max_iter : 알고리즘의 최대 반복 횟수이며, 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료합니다.
KMeans는 사이킷런의 비지도학습 클래스와 마찬가지로 fit() 또는 fit_transform() 메서드를 이용해 수행하면 됩니다. 이렇게 수행된 KMeans 객체는 군집화 수행이 완료돼 군집화와 관련된 주요 속성을 가집니다.
- labels_ : 각 데이터가 속한 군집 중심점 레이블
- cluster_centers_ : 각 군집 중심점 좌표(shape : (군집 개수, 피처 개수)). 이를 이용하면 군집 중심점 좌표가 어디인지 시각화할 수 있습니다.
K-평균 알고리즘을 이용해 붓꽃 종류 분류 데이터를 군집화해봅시다. 꼿받침, 꽃잎의 길이에 따라 군집화가 어떻게 결정되는 지 확인하고, 이를 실제 분류 레이블과 비교해봅시다.

붓꽃 데이터 세트를 3개의 군집으로 군집화해봅시다. fit() 메서드를 수행하여 데이터 세트에 대한 군집화 결과가 kmans 객체 변수로 반환됐습니다. 해당 객체의 labels_ 속성을 확인하여 각 데이터가 어떤 군집에 속하는 지를 알 수 있습니다.
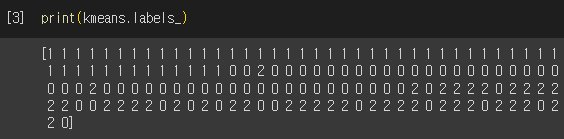
labels_ 값이 0, 1, 2이며, 이는 각 데이터가 첫 번째, 두 번째, 세 번째 군집에 속함을 의미합니다.

실제 붓꽃 품종과 얼마나 차이가 나는지를 비교하여 군집화가 얼마나 효과적으로 수행됐는지를 확인해봅시다. 붓꽃 데이터 세트의 target 값을 'target' 칼럼으로, 앞에서 구한 labels_를 'cluster' 칼럼으로 지정하여 groupby 연산을 통해 실제 분류값과 군집화 분류값을 비교합시다.
분류 타깃값이 0인 데이터는 1번 군집으로 모두 잘 군집화되었습니다. 타겟값이 1인 데이터 중 2개만 2번 군집으로 그루핑되었고, 나머지 48개의 데이터는 모두 0번 군집으로 그루핑됐습니다. 하지만 타겟값이 2인 데이터는 0번 군집과 2번 군집에 분산돼어 그루핑됐습니다.

이번에는 군집화 결과를 시각화해봅시다. 2차원 평면상에 개별 데이터를 시각화하려고 합니다. 붓꽃 데이터 세트의 피처가 4개이므로, PCA를 통해 2개의 피처로 축소합시다.
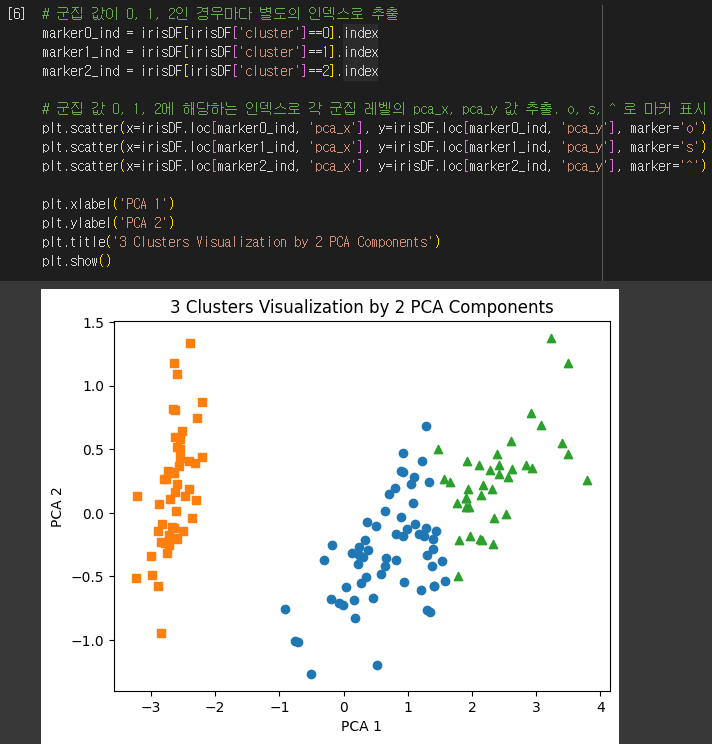
군집 별로 다른 마커로 PCA를 진행한 데이터의 피처1, 피처2를 시각화 했습니다. cluster1를 나타내는 네모 모양의 마커는 명확히 다른 군집과 잘 분리돼어 있습니다. 하지만 cluster0과 cluster2를 나타내는 군집은 상당 수준 분리돼 있지만, 아주 명확한 경계를 가지진 않습니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 군집 평가(Cluster Evaluation) (0) | 2023.05.25 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 군집화 알고리즘 테스트를 위한 데이터 생성 (0) | 2023.05.25 |
| 파이썬 머신러닝 완벽 가이드 : NMF(Non-Negative Matrix Factorization) (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : SVD(Singular Value Decomposition) (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : LDA(Linear Discriminant Analysis) (0) | 2023.05.22 |