
티스토리 뷰
LDA(Linear Discriminant Analysis)는 선형 판별 분석법으로 불리면, PCA와 매우 유사합니다. LDA는 PCA와 유사하게 데이터를 저차원 공간에 투영해 차원을 축소하는 기법이지만, 중요한 차이점이 존재합니다.
LDA는 지도학습의 분류에서 사용하기 쉽도록 개별 클래스를 분별할 수 있는 기준을 최대한 유지하면서 차원을 축소합니다. PCA는 데이터의 변동성이 가장 큰 축을 찾았지만, LDA는 데이터의 결정값 클래스를 최대한으로 분리할 수 있는 축을 찾습니다.
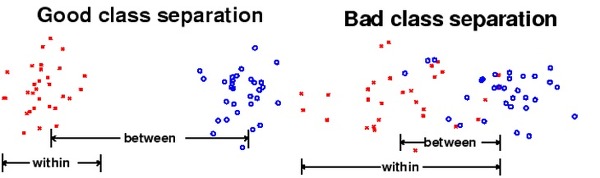
LDA는 클래스 분리를 최대화하는 축을 찾기 위해 클래스 간 분산(between-class scatter)과 클래스 내부 분산(within-class scatter)의 비율을 최대화하는 방식으로 차원을 축소합니다. 즉, 클래스 간 분산은 최대한 크게 가져가고, 클래스 내부 분산은 최대한 작게 가져가는 방식입니다.
LDA를 구하는 절차는 PCA와 유사하나, 가장 큰 차이점은 공분산 행렬이 아니라 클래스 간 분산과 클래스 내부 분산 행렬을 기반으로 고유벡터를 구하고 데이터를 투영한다는 점입니다.
- 클래스 내부와 클래스 간 분산 행렬을 구합니다. 두 행렬은 데이터의 결정 값 클래스별로 개별 피처의 평균 벡터를 기반으로 구합니다.
- 클래스 내부 분산 행렬을 $S_{W}$, 클래스 간 분산 행렬을 $S_{B}$라고 한다면, $S_{W}^{T}S_{B}$를 고윳값 분해함으로써 고유벡터를 얻을 수 있습니다.
- 고윳값이 가장 큰 순으로 K개(LDA 변환 차수만큼) 추출합니다.
- 추출된 고윳갑에 해당하는 고유벡터를 이용해 데이터를 선형 변환합니다.
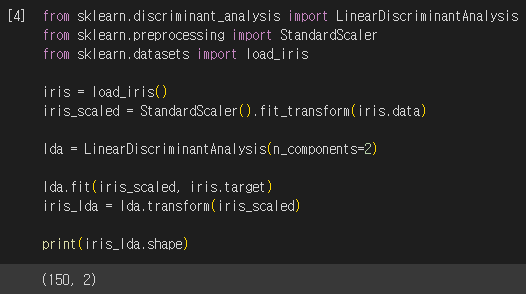
붓꽃 데이터 세트를 사이킷런의 LDA 클래스를 이용하여 변환했습니다. PCA 클래스와 마찬가지로 n_components 인자를 지정할 수 있습니다. 이때 중요한 점은, LDA는 실제로는 PCA와 다르게 비지도학습이 아닌 지도학습이라는 사실입니다. 즉, fit() 메서드를 호출 할 때 클래스의 결정값이 필요합니다. 코드에서도 fit() 메서드에 iris.target 객체가 인자로 입력된 것을 유의합시다.

이전과 마찬가지로 붓꽃의 품종에 따라 다른 마커로 변환된 피처를 시각화해봅시다.

PCA로 변환된 데이터와 좌우 대칭 형태로 많이 닮아 있음을 확인할 수 있습니다. 하지만 "versicolor"와 "verginica" 품종을 더욱 잘 구분한 것으로 보입니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : NMF(Non-Negative Matrix Factorization) (0) | 2023.05.23 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : SVD(Singular Value Decomposition) (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : PCA 실습 - UCI 신용카드 고객 데이터 세트 (0) | 2023.05.22 |
| 파이썬 머신러닝 완벽 가이드 : 차원 축소 개요와 PCA(Principal Component Analysis) (0) | 2023.05.22 |
| 파이썬 머신러닝 완벽 가이드 : 캐글 주택 가격 예측 (고급 회귀 기법) (1) | 2023.05.13 |