
티스토리 뷰
사이킷런은 다양한 유형의 군집화 알고리즘을 테스트해 보기 위한 간단한 데이터 생성기를 제공합니다. 대표적인 API로 make_blobs()와 make_classification()이 있습니다. make_blobs()는 개별 군집의 중심점과 표준 편차 제어 기능이 추가돼 있으며, make_classification()은 노이즈를 포함한 데이터를 만드는 데 유용하게 사용할 수 있습니다. 둘 다 분류 용도로도 테스트 데이터 생성이 가능합니다.
make_blobs()의 사용법을 간략히 알아봅시다. 해당 메서드의 반환값은 피처 데이터 세트와 타깃(군집) 데이터 세트를 담은 튜플입니다. 호출 파라미터는 다음과 같습니다.
- n_samples: 생성할 총 데이터의 개수. 디폴트는 100.
- n_features : 데이터의 피처 개수. 시각화를 목표로 할 경우 보통 2로 설정한다.
- centers : 정수값일 경우 군집의 개수를 나타내며, ndarray일 경우 개별 군집 중심점의 좌표.
- cluster_std : 생성될 군집 데이터의 표준 편차. 군집이 여러 개이면 리스트(예 : [0.8, 1.2 0.6])형태.

3개의 군집화 기반 분포도를 가지는 2개의 피처를 가지는 200개의 데이터를 만들었습니다. 군집의 값은 [0, 1, 2]이며, 200개의 데이터는 각각의 군집에 67, 67, 66개로 균일하게 분포돼 있는 것을 확인할 수 있습니다.

해당 데이터 세트를 DataFrame 객체로 만들어서 더 편리하게 가공할 수 있게끔합시다.

만들어진 피처 데이터 세트를 시각화해봅시다. 군집에 따라 마커를 다르게 하여 산점도를 그려봤습니다.
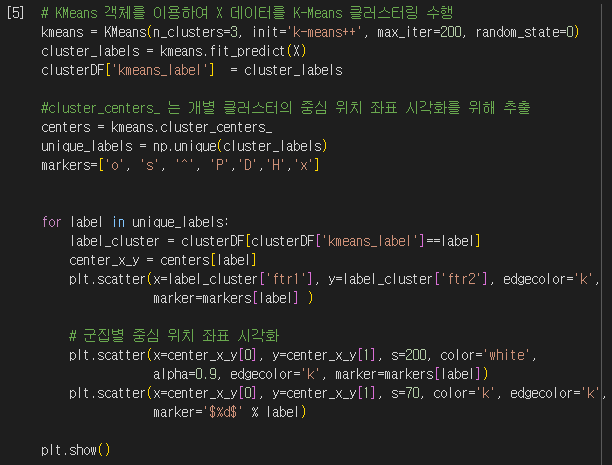
해당 데이터 세트에 K-평균 군집화를 수행한 뒤에, 군집화된 결과를 시각화 해봅시다. KMenas 객체의 fit_predict(X) 메서드를 수행하여 K-평균 군집화를 수행합니다. 군집화 된 결과를 DataFrame에 'kmeans_label' 칼럼으로 추가해줍시다. KMeans 객체의 cluster_centers_ 속성은 개별 군집의 중심 위치 좌표입니다.

make_blobs()의 타깃값(군집)과 kmeans_label은 군집 번호를 의미하는데, 이는 서로 다른 값으로 매핑될 수 있습니다. 즉, 산점도의 마커가 서로 다를 수 있습니다.

make_blobs()의 타깃값과 kmeans_label의 값의 분포를 서로 비교해보면, 각 군집이 서로 다른 값으로 매핑되었지만 K-평균 알고리즘을 통해 찾은 군집이 원래의 군집과 매우 비슷한 것을 알 수 있습니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 평균 이동(Mean Shift) (0) | 2023.05.25 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 군집 평가(Cluster Evaluation) (0) | 2023.05.25 |
| 파이썬 머신러닝 완벽 가이드 : K-means clustering (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : NMF(Non-Negative Matrix Factorization) (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : SVD(Singular Value Decomposition) (0) | 2023.05.23 |