
티스토리 뷰
앞의 붓꽃 데이터 세트의 경우 결괏값에 품종을 뜻하는 타깃 레이블이 있었고, 군집화 결과를 이 레이블과 비교하여 군집화가 얼마나 잘 수행됐는지를 평가할 수 있었습니다. 하지만 대부분의 군집화 데이터 세트는 이렇게 비교할만한 타깃 레이블을 가지고 있지 않습니다.
군집화는 분류(Classification)과 유사해 보일 수 있으나 많이 다릅니다. 데이터 내에 숨어 있는 별도의 그룹을 찾아서 의미를 부여하거나, 같은 분류값이라도 그 안에서 더 세분화된 군집화를 진행할 수 있습니다. 또한. 서로 다른 분류 값의 데이터도 더 넓은 군집화 레벨화 등의 영역을 가집니다.
그렇다면 군집화가 잘 됐는지 평가할 수 있는 지표는 무엇이 있을까요? 비지도학습의 특성상 어떠한 지표라도 정확한 성능을 평가하긴 어렵습니다. 그럼에도 군집화의 성능을 평가하는 대표적인 방법으로 실루엣 분석을 사용합니다.
실루엣 분석(silhouette analysis)은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타냅니다. 군집화가 효율적으로 수행됐다는 것은 각 군집이 다른 군집과는 거리가 떨어져 있고, 동일 군집 내의 데이터끼리는 가깝게 잘 뭉쳐있다는 것을 의미합니다. 군집화가 잘 됐을수록 개별 군집은 비슷한 정도의 여유공간을 가지고 떨어져 있을 것입니다.
실루엣 분석은 실루엣 계수(silhouette coefficient)를 기반으로 합니다. 실루엣 계수는 개별 데이터가 가지는 군집화 지표입니다. 실루엣 계수는 데이터가 각 군집 내의 데이터와 얼마나 가깝게 군집화돼 있고, 다른 군집의 데이터와는 얼마나 멀리 분리돼 있는지를 나타내는 지표입니다.

실루엣 계수를 구하는 법을 알아봅시다. 가령 현재 초록색으로 마킹된 군집의 데이터 i의 실루엣 계수를 구한다고 합시다. $a(i)$는 해당 데이터 i와 같은 군집 내에 있는 다른 데이터 포인트와의 거리의 평균값입니다. $b(i)$는 해당 데이터 i에서 가장 가까운 다른 군집에 대해, 그 군집의 모든 데이터와의 거리의 평균값입니다. 데이터 i의 실루엣 계수 $s(i)$는 $(b(i)-a(i)) / \max (a(i), b(i))$입니다. 실루엣 계수는 -1 ~ 1까지의 값을 가질 수 있으며, 1에 가까울수록 두 군집간의 거리가 멀다는 뜻입니다.
사이킷런은 실루엣 분석과 관련된 API를 제공합니다.
- sklearn.metrics.silhouette_samples(X, labels, metric='euclidean', **kwds) : 인자로 피처 데이터와 군집 레이블 값을 입력하면 각 데이터의 실루엣 계수를 반환합니다.
- sklearn.metrics.silhoueete_score(X, labels, metric='eucildean', sample_size=None, **kwds) : 인자로 피처 데이터와 군집 레이블 값을 입력하면 전체 데이터의 실루엣 계수의 평균값을 반환합니다. 일반적으로 이 값이 높을수록 군집화가 어느 정도 잘 됐다고 판단 가능하지만, 값이 높을수록 더 좋은 군집화라고 할 순 없습니다.
좋은 군집화는 전체 실루엣 계수의 평균값이 1에 가까운 높은 값이어야 하며, 개별 군집의 실루엣 계수의 평균값의 편차가 크지 않아야 합니다. 만약 전체 실루엣 계수의 평균값은 높지만, 특정 군집의 실루엣 계수의 평균값은 유난히 높고 다른 군집들의 실루엣 계수의 평균값은 낮다면 좋은 군집화라고 할 수 없습니다.

붓꽃 품종 데이터를 K-평균 알고리즘으로 군집화를 한 뒤, 그 결과를 실루엣 분석으로 평가해봅시다.
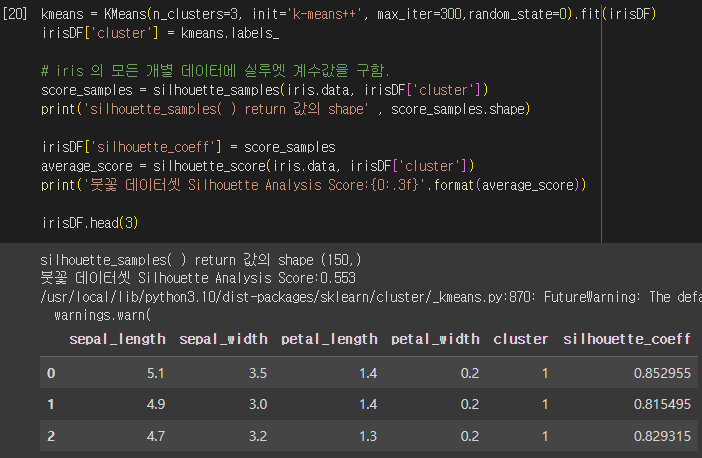
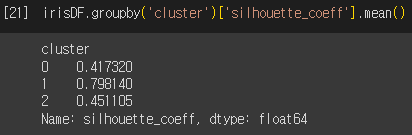
군집화에 대한 평균 실루엣 계수의 값은 약 0.553입니다. 각 군집에 대한 평균 실루엣 계수 값도 출력해봅시다. 군집1의 경우 평균 실루엣 계수가 높지만, 군집0과 군집2의 평균 실루엣 계수는 상대적으로 낮은 것을 보아 군집화가 효율적으로 수행되었다고 보긴 어렵습니다.
군집별 평균 실루엣 계수의 시각화를 통해 어떤 데이터 세트를 몇 개의 군집으로 군집화해야 할 지를 최적화할 수 있습니다.

가령, 4개의 클러스터로 나누어진 2차원 피처를 가지는 500개의 데이터를 각각 2, 3, 4, 5개의 군집의 개수로 군집화를 수행해보면서 클러스터 별 실루엣 계수의 평균값을 시각화해봅시다. 이때 visualize_silhouette() 메서드는 따로 본문에 싣지는 않겠습니다.
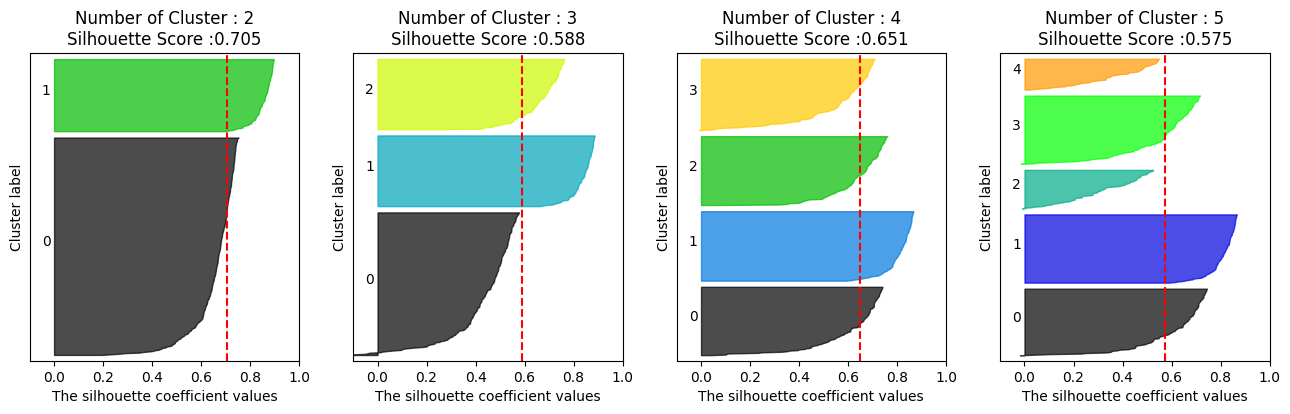
시각화된 그래프를 해석하는 방법을 알아봅시다. 먼저, 가장 왼쪽의 그래프를 봅시다. 위의 데이터를 두 개의 클러스트로 군집화를 수행한 경우의 그래프입니다. 각 군집은 그래프의 y축에 1, 0으로 표시되어 있습니다. 각 군집에 대해 그래프의 x축 값은 해당 군집에 속하는 각 데이터의 실루엣 계수입니다. 그 값이 들쭉날쭉하지 않을 것을 보아 실루엣 계수는 정렬되어 시각화 되었다는 것을 유추할 수 있습니다. 그래프의 빨간 점선으로 표시된 값은 모든 데이터의 실루엣 계수의 평균값입니다.
이를 토대로 첫 번째 그래프를 해석해봅시다. 군집1에 속하는 모든 데이터의 실루엣 계수는 모든 실루엣 계수의 평균값보다 높습니다. 그러나 군집0의 경우 과반수의 데이터의 실루엣 계수는 모든 실루엣 계수의 평균값보다 낮습니다.
모든 그래프 중에, 클러스의 개수가 4개인 경우의 군집화가 각 군집간의 평균 실루엣 계수의 편차가 가장 고른 것을 확인할 수 있습니다. 비록 전체 실루엣 계수의 평균은 클러스터를 두 개로 군집화한 경우인 0.705보다 작지만, 4개의 군집으로 군집화한 경우가 가장 이상적인 군집화라고 판단할 수 있습니다.

붓꽃 품종 분류 데이터 세트에 대해서도 여러 수의 클러스터 개수로 군집화를 수행한 뒤, 가장 효율적인 군집화는 어떤 것인지 판단해봅시다.

붓꽃 품종 분류 데이터의 경우 2개의 클러스터를 기반으로 군집화를 수행하는 것이 가장 좋아보입니다.
실루엣 계수를 통한 K-평균 군집 평가 방법은 직관적으로 이해하기 쉽지만, 각 데이터에 대해 다른 데이터와의 거리를 반복적으로 계산해야 하므로 데이터가 커지면 수행 시간이 크게 증가합니다. 이 경우 군집별로 임의의 데이터를 샘플링해 실루엣 계수를 평가하는 방안을 고민해야 합니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 평균 이동(Mean Shift) (0) | 2023.05.25 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 군집화 알고리즘 테스트를 위한 데이터 생성 (0) | 2023.05.25 |
| 파이썬 머신러닝 완벽 가이드 : K-means clustering (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : NMF(Non-Negative Matrix Factorization) (0) | 2023.05.23 |
| 파이썬 머신러닝 완벽 가이드 : SVD(Singular Value Decomposition) (0) | 2023.05.23 |