
티스토리 뷰
1. 가중치 초기화의 중요성
신경망의 가중치를 어떻게 초기화할지에 따라 학습의 성패가 갈린다. 단순하게 모든 가중치를 0으로 초기화 해보자(정확히는 모든 가중치를 동일한 값으로 설정해보자). 이 신경망은 학습이 제대로 되지 않는다. 그 이유는 오차역전파에서 모든 가중치가 똑같은 값으로 갱신되기 때문이다.
예를들어 2층 신경망이 있다고 하자. 1층과 2층 사이에 모든 가중치가 0이라면, 순전파 때 두 번째 층의 뉴런에 모두 같은 값이 전달된다. 이는 역전파때 두 번째 층의 가중치가 모두 똑같이 갱신된다는 뜻이다. 이는 가중치를 여러 개 갖는 의미를 상실시킨다.
이렇듯 가중치가 고르게 되어버리는 상황을 방지하려면 가중치의 초깃값을 무작위로 설정해야 한다.
2. 은닉층의 활성화값 분포
은닉층의 활성화값(활성화 함수의 출력값) 분포를 관찰하면 중요한 정보를 얻을 수 있다. 앞으로 가중치 초깃값에 따라 은닉층의 활성화값이 어떻게 변화하는지 실험할 것이다. 활성화 함수로 시그모이드 함수를 사용하는 신경망에 무작위로 생성한 입력 데이터를 흘리며 각 층의 활성화값 분포를 관찰하자.
신경망은 5층이며, 각 층의 뉴런은 100개씩이다. 입력 데이터로 1000개의 데이터를 정규분포로 무작위로 생성하였다.

먼저 표준편차가 1인 정규분포로 입력 데이터를 생성했을 때의 결과이다. 각 층의 활성화값은 0과 1에 치우쳐 있다. 시그모이드 함수는 출력값이 0과 1에 가까워질수록 미분값이 0에 가까워진다. 그래서 이 신경망의 역전파 과정에서 기울기 값이 점점 작아지면서 사라져갈 것을 예측할 수 있다. 이 현상을 기울기 소실(gradient vanishing)이라고 한다.
역전파의 특성상 신경망의 층이 깊어질수록 역전파 과정에서 기울기 소실 문제가 심각해진다.
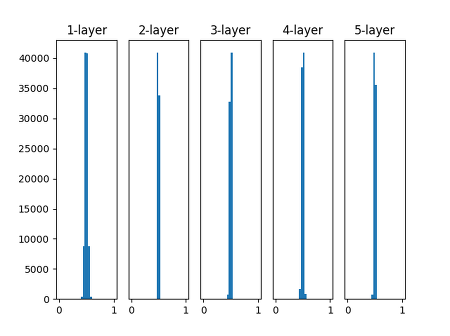
이번에는 정규분포의 표준편차를 0.01로 바꿔 본 결과이다. 활성화값이 0.5 부근에 몰려있다. 시그모이드 함수는 입력값이 0.5인 부근에서 미분값이 크므로 기울기 소실 문제는 상대적으로 문제가 되지 않는다. 하지만 활성화값이 특정값에 몰려있다는 사실은 신경망의 표현력에 큰 문제가 있다는 뜻이다.
다수의 뉴런이 거의 같은 값을 출력하고 있으니 여러 개의 뉴런을 둔 의미가 상실되었다는 뜻이다. 그래서 뉴런의 활성화값이 치우치면 신경망의 표현력을 제한한다.
각 층의 활성화값은 적당히 고루 분포되어야 한다. 층과 층 사이에 적당하게 다양한 값이 흐르게 해야 신경망 학습이 효율적으로 이루어지기 때문이다. 치우친 데이터가 흐르면 기울기 소실이나 표현력 제한 문제에 빠져 학습이 제대로 되지 않는 경우가 생긴다.
3. Xavier 초기화
각 층의 활성화값을 광범위하게 분포시킬 목적으로 가중치의 적절한 초기화 방법을 찾고자 한 방법 중 하나이다. 핵심은 앞 계층의 노드가 $n$개라면 표준편차가 $\sqrt {1 \over n}$인 분포를 사용하면 된다는 점이다(Xavier 기법을 제안하는 논문에선 앞 층 노드의 수 외에 다음 층의 노드 수도 고려하여 가중치 초기화를 진행하지만, 여기선 단순화했다).

앞 층의 뉴런이 많을수록 대상 노드의 초깃값으로 설정하는 가중치의 범위가 좁게 퍼진다.
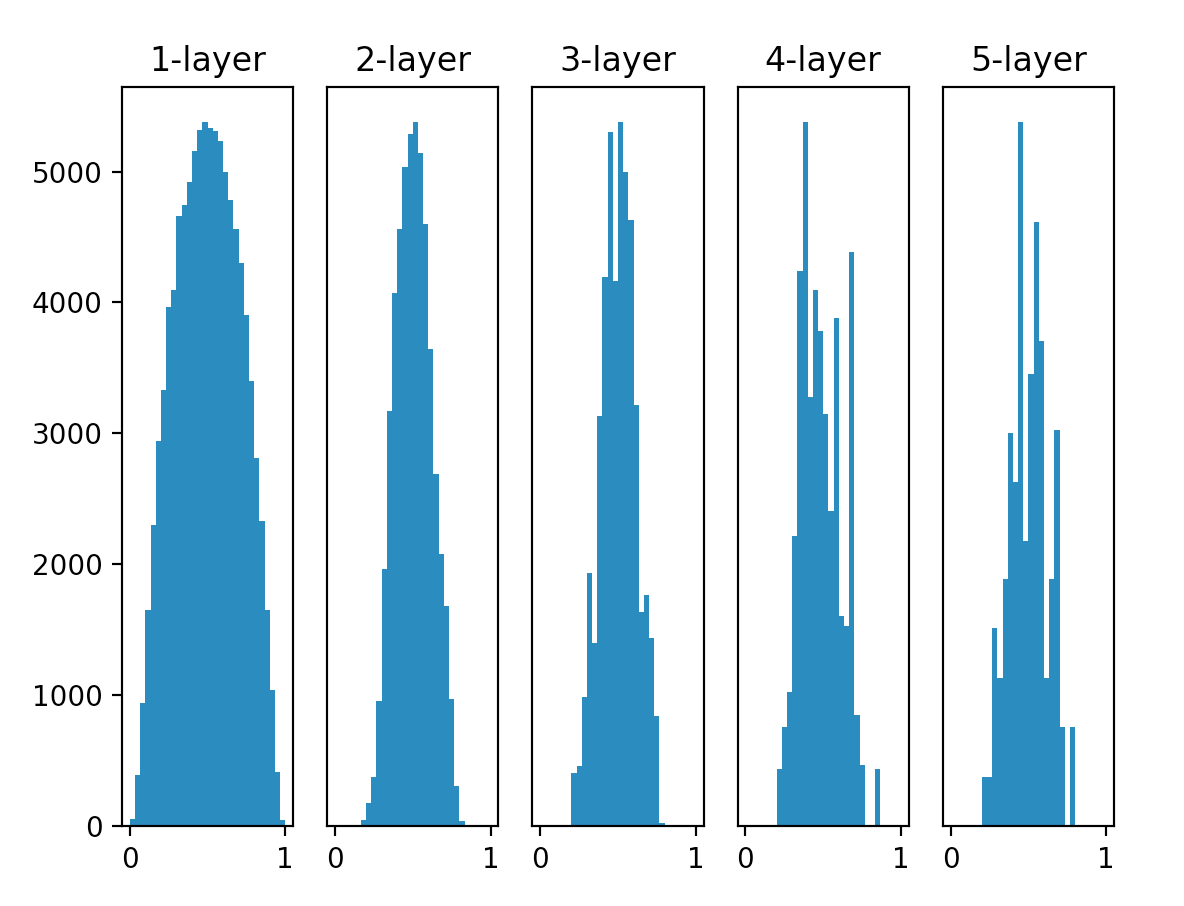
Xavier 초기화를 적용한 결과이다, 층이 깊어지면서 고르게 분포된 형태가 다소 일그러지지만, 앞서 본 방식보다는 확실히 값이 다양하게 분포되어 있다. 각 층마다 흐르는 데이터가 다양하게 분포되어 있으므로, 시그모이드 함수의 표현력도 제한받지 않고 효율적인 학습이 이루어질 것으로 기대된다.
더불어, 층이 깊어질수록 분포가 일그러지는 현상을 방지하려면 시그모이드 함수 대신 tanh 함수를 활성화 함수로 사용하면 된다. 두 함수의 개형은 S자로 비슷하지만, 시그모이드 함수는 $(0, 0.5)$에서 대칭인 반면 tanh 함수는 $(0, 0)$에서 대칭이다. 신경망의 활성화 함수용으로는 원점 대칭인 함수가 바람직하다고 알려져 있다.
4. He 초기화
시그모이드가 아니라 ReLU 함수를 활성화 함수로 이용하는 경우 He 초기화를 많이 사용한다. He 초기화는 앞 층의 뉴런이 $n$개일 때, 표준편차가 $\sqrt {2 \over n}$ 인 정규분포로 가중치 초기화를 한다.

활성화 함수로 ReLU를 사용했을 때, 가중치 초기화 방법에 따른 활성화값 분포이다. 표준편차가 0.01인 정규분포를 사용한 경우 신경망에 아주 작은 데이터가 흐르고 있다. 이는 역전파 때 가중치의 기울기 역시 작아진다는 뜻이다. 이는 학습에 중대한 문제이므로, 실제로도 학습이 거의 이루어지지 않을 것이다.
Xavier 초기화의 경우 층이 깊어지면서 치우침의 정도가 커진다. 학습시 기울기 소실 문제가 크게 발생한다.
He 초기화는 모든 층에서 균일한 분포를 보여준다.
실험 결과를 바탕으로, 활성화 함수로 ReLU를 사용할 때는 He 초기화를, sigmoid나 tanh 등의 S자 개형의 함수를 사용할 경우 Xavier 초기화를 사용하면 좋다는 사실을 얻었다.
5. MNIST 학습 결과
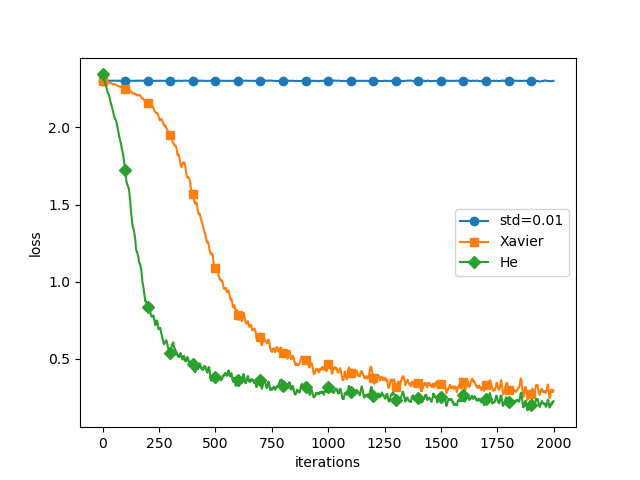
실제 신경망 학습을 통해 가중치 초기화 방법의 중요성을 알아보자. 학습한 신경망은 5층 짜리 신경망이며, 각 층의 뉴런은 100개이다. 활성화 함수로 ReLU를 썼다.
표준편차가 0.01인 정규분포로 가중치 초기화를 했을 때 학습이 아예 안 되었다. 순전파때 너무 작은 값이 흐르고, 역전파 때 기울기가 작아져 가중치가 거의 갱신되지 않기 때문이다.
'밑바닥부터 시작하는 딥러닝1' 카테고리의 다른 글
| 배치 정규화 (0) | 2023.12.09 |
|---|---|
| 매개변수 갱신 방법 (2) | 2023.12.05 |
| 오차역전파법 (0) | 2023.12.03 |
| 학습 알고리즘 (0) | 2023.11.30 |
| 경사 하강법 (0) | 2023.11.26 |