
티스토리 뷰
1. 확률적 경사 하강법(SGD)
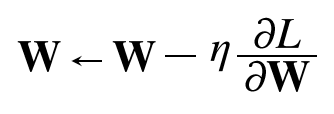
SGD는 그라디언트의 방향으로 일정 거리만큼 가는 단순한 매개변수 갱신 방법이다.

SGD는 단순하고 구현도 쉽지만, 문제에 따라서 비효율적인 경우가 있다. 아래와 같은 비등방성 함수에서 그렇다. 비등방성 함수란 각 지점에서의 기울기가 전체에서 한 점만을 가리키지 않는 함수라고 이해하면 된다.

함수의 최솟값을 가지는 좌표는 $(0, 0)$이지만, 대부분의 지점에서 기울기는 $(0, 0)$ 방향을 가리키지 않는다. 이 함수에 SGD를 적용해보자.

갱신 경로가 지그재그로, 비효율적인 탐색 결과를 볼 수 있다. 이런 함수에는 SGD 같이 무작정 기울어진 방향으로 진행하는 단순한 방식보다 더 영리한 방법이 필요하다.
또한 SGD가 지그재그로 탐색하는 근본 원인이 기울기 방향이 최솟값과 다른 방향이기 때문이라는 점도 생각해 볼만한 주제이다.
이러한 SGD의 단점을 개선한 모멘텀, AdaGrad, Adam 방법을 소개한다.
2. 모멘텀
모멘텀은 운동량을 뜻하는 단어로, 물리와 관계가 있다.
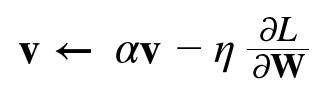

$v$라는 변수가 새로 등장하는데, 이는 물리에서 속도(velocity)이다. 첫 번째 식은 기울기 방향으로 힘을 받아 물체가 가속된다는 물리 법칙을 나타낸다. 모멘텀은 공이 그릇의 바닥을 구르는 듯한 움직임을 보여준다.
$\alpha v$항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할을 한다. $\alpha$는 보통 $0.9$로 설정한다. 물리에서의 지면 마찰이나 공기 저항에 해당한다.

모멘텀으로 아까 그 함수의 최적화 문제를 풀어보았다. 그림에서 보듯 모멘텀의 갱신 경로는 공이 그릇 바닥을 구르듯 움직인다. SGD와 비교하여 지그재그 정도가 덜하다.
이는 $x$축의 힘은 아주 작지만 방향은 변하지 않아 한 방향으로 일정하게 가속하기 때문이다. $y$축의 힘은 크지만 위아래로 번갈아 받아서 상충하여 $y$축 방향의 속도는 안정적이지 않다. 전체적으로 SGD보다 $x$축 방향으로 빠르게 다가가 지그재그 움직임이 줄어들었다.
3. AdaGrad
신경망 학습에서 학습률($\eta$) 값은 중요하다. 값이 너무 작으면 학습 시간이 길어지고, 너무 크면 발산하여 학습이 안 된다. 학습률을 정하는 효과적인 기술로 학습률 감소(decay)가 있다. 학습을 진행하면서 학습률을 점차 줄여가는 방법이다.
가장 간단한 방법은 모든 매개변수의 학습률을 일괄적으로 낮추는 것이다. 이를 발전시킨 것이 AdaGrad이다. AdaGrad는 각 매개변수의 학습률을 적응적으로 조정한다.

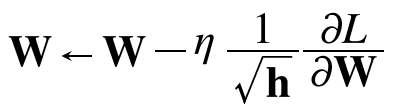
$h$라는 변수가 새로 등장한다. $h$는 기존 기울기 값을 제곱하여 계속 더한 값이다. $\odot$은 행렬의 원소별 곱셈을 의미한다. 매개변수를 갱신할 때 $1 \over \sqrt h$를 곱해 학습률을 조정한다. 많이 움직인(크게 갱신된) 매개변수의 학습률이 낮아진다는 뜻이다.
AdaGrad로 학습을 무한히 진행하면 어느 순간 갱신량이 0이 되어 버린다. 이 문제를 개선한 기법이 RMSProp이다. RMSProp은 과거의 모든 기울기를 균일하게 더해나가는 것이 아니라, 지수이동평균(Exponential moving average)을 이용하여 과거 기울기의 반영 규모를 기하급수적으로 감소시킨다.
갱신시 $h=0$인 경우를 방지하기 위해 $h$에 매우 작은 값을 더해서 사용한다.

AdaGrad로 위 함수의 최적화 문제를 풀어봤다. 최솟값을 향해 효율적으로 움직인 것을 볼 수 있다. $y$축 방향은 기울기가 커서 처음에는 크게 움직이지만, 그 움직임에 비례해 갱신 정도도 큰 폭으로 작아지도록 조정된다. 그 결과 $y$축 방향의 갱신 강도가 빠르게 약해지고, 지그재그 정도가 줄어든다.
4. Adam
공이 바닥을 구르는 듯한 움직임을 보여주는 모멘텀과 AdaGrad를 융합하자는 생각에서 출발한 기법이 Adam이다. 실제 이론은 다소 복잡하지만 직관적으로는 이렇게 이해해도 무리가 없다. Adam을 정확하게 이해하려면 반드시 원 논문을 읽어보길 권장한다. 또, 하이퍼파라미터의 편향 보정이 진행된다는 점도 Adam의 특징이다.

Adam은 모멘텀과 같은 부드러운 움직임을 보여주지만, 모멘텀보다 경로의 흔들림이 적다. 이는 각 매개변수의 갱신 강도를 적응적으로 조정했기 때문이다.
5. 어떤 갱신 방법을 사용해야 되는가
어떤 옵티마이저를 사용해야 하는 지는 풀어야 하는 문제, 적용하는 하이퍼파라미터 등에 따라 다르다.
'밑바닥부터 시작하는 딥러닝1' 카테고리의 다른 글
| 배치 정규화 (0) | 2023.12.09 |
|---|---|
| 가중치 초기화 방법 (0) | 2023.12.09 |
| 오차역전파법 (0) | 2023.12.03 |
| 학습 알고리즘 (0) | 2023.11.30 |
| 경사 하강법 (0) | 2023.11.26 |