
티스토리 뷰
캐글에서 제공하는 House Prices : Advanced Regression Techniques 데이터 세트를 이용해 회귀 분석을 더 심층적으로 알아봅시다. 79개의 변수로 구성된 이 데이터는 미국 아이오와 주의 에임스(Ames) 지방의 주택 가격 정보를 가지고 있습니다. 자전거 대여 예측 예제와 동일하게 RMSLE 값이 평가 지표로 제시되었습니다. 가격이 비싼 주택일수록 예측 결과 오류가 전체 오류에 미치는 비중이 높으므로 이것을 상쇄하기 위해 오류값을 로그로 변환한 RMSLE를 사용하는 것입니다.

본 실습에서는 많은 데이터 가공을 수행할 것이므로, 원본 DataFrame을 따로 보관해놓겠습니다. 타겟값은 맨 마지막 칼럼인 SalePrice입니다.

데이터 세트의 크기와 피처의 타입, Null이 있는 칼럼과 그 건수를 내림차순으로 출력합시다. 데이터 세트는 1460개의 레코드와 81개의 피처로 구성되어 있으며, 피처의 타입은 숫자형은 물론 문자형도 많이 있습니다. 전체 1480개의 레코드 중 PoolQC, MiscFeatues, Alley, Fence는 1000개가 넘는 데이터가 결손값입니다. 이들은 그냥 드랍하겠습니다.

학습을 수행하기 전에 타깃값의 분포를 확인합시다. 분포가 중심에서 왼쪽으로 치우친 형태로, 정규분포에서 벗어나 있는 것을 확인할 수 있습니다.

보다 더 정규 분포스럽게 분포를 변환하기 위해 타깃값에 로그 변환을 취했습니다.

지금까지 언급한 전처리를 수행하겠습니다. 일단 타깃값에 로그 변환을 취합니다. 결손값이 너무 많은 피처와 단순 식별자인 "Id" 피처는 드랍합시다. 숫자형 피처의 결손값은 각 피처의 평균값으로 대체합시다. 결손값 대체 중, 문자열 피처는 제외하고 자동으로 숫자형 피처에 대해서만 평균값 대체가 수행됩니다. 결손값을 가지는 피처를 출력해보면, 더 이상 숫자형 피처는 남아있지 않은 것을 확인할 수 있습니다.
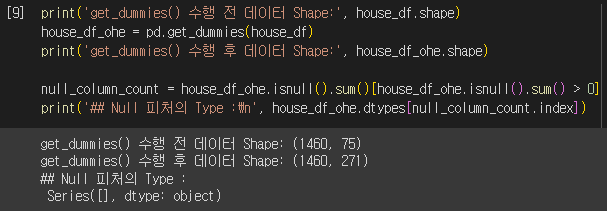
문자열 피처의 경우 원-핫 인코딩을 수행합시다. 판다스의 get_dummies() 메서드로 원-핫 인코딩을 수행할 경우 Null값은 자동으로 모든 값이 0인 것으로 인코딩되기 때문에 별도의 결손값 대체 로직이 필요하지 않습니다. 원-핫 인코딩을 수행하면 당연히 칼럼의 개수가 증가하게 됩니다. 모든 문자열 피처를 원-핫 인코딩한 후 칼럼의 개수는 75개에서 271개로 늘어났습니다. 또한 더 이상 결손값을 가지는 피처가 없는 것을 볼 수 있습니다. 이 정도에서 데이터 세트의 기본적인 가공을 마치도록 하겠습니다.
앞에서, 모델의 예측 성능 평가는 RMSLE로 한다고 했습니다. 그런데 이미 타깃값인 SalePirce가 로그 변환됐습니다. 모델의 예측값 역시 로그 변환된 타깃값을 기반으로 학습하므로 원본 SalePrice 예측값의 로그 변환 값입니다. 그러므로 예측 결과 오류에 RMSE를 적용하면 실제로는 RMSLE를 구한 것입니다. get_rmse(model)은 단일 모델의 RMSE 값을, get_rmses(models)는 get_rmse()를 이용해 여러 모델의 RMSE 값을 반환합니다.

일단은 기본적인 세 모델로 학습을 수행하고 RMSE를 측정해봅시다. 라쏘 회귀의 경우 타 회귀 방식보다 예측 성능이 많이 떨어집니다. 라쏘의 경우 하이퍼 파라미터 튜닝이 필요해보입니다.

그보다 먼저, 피처별 회귀 계수를 시각화해봅시다. 피처의 개수가 많으니, 회귀 계수 값의 크기에 따라 상위 10개, 하위 10개의 피처에 대해서 시각화를 진행합시다.

세 모델의 회귀 계수를 동시에 시각화합니다.

LinearRegression과 Ridge의 경우 회귀 계수가 유사한 형태로 분포돼 있습니다. 하지만 라쏘는 전체적으로 회귀 계수 값이 너무 작으며, YearBuilt의 회귀 계수가 가장 크고 다른 피처의 회귀 계수는 너무 작습니다.

혹시 학습/테스트 데이터를 분할하는 과정에 문제가 있어서 이러한 결과가 나왔을 수도 있으니, 이번에는 train_test_split() 메서드를 이용하지 않고 전체 데이터 세트를 5개의 교차 검증 폴트 세트로 분할하여 평균 RMSE를 측정해봅시다.
5개의 폴드 세트로 학습한 후에 평가해도 여전히 라쏘의 성능이 떨어집니다. 릿지와 라쏘 모델의 alpha 파라미터를 변화시키면서 성능을 끌어올려봅시다.

라쏘 모델의 경우 alpha 값을 최적화 한 뒤 예측 성능이 많이 좋아졌습니다. 다시 train_test_split() 메서드로 학습 데이터와 테스트 데이터를 분리한 뒤, 최적의 alpha 값으로 설정한 릿지와 라쏘 모델로 학습을 수행하고 회귀 계수를 다시 시각화해봅시다.


alpha 값을 최적화했더니 테스트 데이터에 대한 릿지와 라쏘 모델의 예측 성능이 많이 개선되었습니다. 모델별 회귀 계수 값도 많이 달라 졌습니다. 라쏘의 회귀 계수 값 분포가 나머지 두 모델의 회귀 계수 값 분포와 상당히 비슷해졌습니다. 다만 라쏘의 경우 릿지에 비해 동일한 피처라도 회귀 계수 값이 상당히 작습니다.
피처 데이터의 분포도를 확인해 봅시다. 타깃값 뿐만 아니라, 지나치게 왜곡된 피처가 존재할 경우 회귀 예측 성능이 저하될 수 있습니다. 모든 숫자형 피처의 데이터 분포도를 확인하여 왜곡 정도를 파악해봅시다.

사이파이 stats 모듈의 skew() 메서드를 이용해 각 피처의 왜곡 정도를 쉽게 출력할 수 있습니다. 일반적으로 skew() 메서드의 반환값이 1 이상인 경우 왜곡이 심하다고 판단하지만, 상황에 따라 편차는 있습니다. 여기서는 반환값이 1 이상인 피처를 추출해 왜곡 정도를 완화하기 위해 로그 변환을 적용하겠습니다.
한가지 주의할 점은, 원-핫 인코딩된 카테고리 숫자형 피처에는 skew() 메서드를 적용하면 안 된다는 점입니다. 따라서 skew() 메서드를 적용할 DataFrame은 원-핫 인코딩이 적용된 house_df_one이 아니라 house_df 입니다.

분포가 왜곡된 숫자형 피처가 꽤 많은 것을 확인할 수 있습니다.

왜곡이 심한 피처에 로그 변환을 취하고, 카테고리형 변수에 대해 다시 원-핫 인코딩을 수행합니다. 이 DataFrame을 기반으로 하여 학습 데이터와 테스트 데이터를 분리합니다. 릿지, 라쏘 모델로 학습을 할 것이므로, print_best_params() 메서드를 이용해 최적 alpha 값과 RMSE를 출력했습니다.
릿지의 경우 최적 alpha 값이 12에서 10으로 변경됐고, 두 모델 모두 피처의 로그 변환 이전과 비교해 릿지는 0.1418에서 0.1275로, 라쏘는 0.142에서 0.1252로 교차 검증의 평균 RMSE 값이 더욱 개선됐습니다.

왜곡이 심한 피처를 로그 변환 한 데이터를 학습한 세 모델의 회귀 계수를 시각화 한 것입니다. 세 모델 모두 GrLivArea, 즉 주거 공간 크기가 회귀 계수가 가장 높은 피처가 됐습니다. 주거 공간 크기가 주택 가격에 미치는 영향이 당연히 제일 높을 것이라는 상식선에서의 결과가 이제야 도출됐습니다.
다음으로 분석할 요소는 이상치 데이터입니다. 특히 회귀 계수가 높은 피처, 즉 예측에 많은 영향을 미치는 중요 피처의 이상치 데이터의 처리가 중요합니다. 먼저 세 모델 모두에서 가장 큰 회귀 계수를 가지는 GrLivArea 피처의 분포를 살펴봅시다.
아무런 전처리도 하지 않은 원본 데이터 세트에서 GrLivArea와 타깃값인 SalePirce의 관계를 시각화해 보겠습니다.

일반적으로 주거 공간이 큰 집일수록 가격이 비싸기 때문에 GrLivArea 피처는 SalePrice와 양의 상관도가 매우 높음을 직관적으로 알 수 있습니다. 하지만 위의 그래프에서 오른쪽 아래에 위치한 두 개의 이상치가 존재합니다. 이 두 개의 데이터는 제거하겠습니다.

데이터 변환이 모두 완료된 DataFrame에서 이상치 데이터를 필터링하겠습니다. GrLivArea와 SalePrice 모두 로그 변환됐으므로, 이를 반영한 조건을 생성한 뒤 불린 인덱싱으로 대상을 찾고 drop() 메서드로 제거합시다.

이상치를 제거한 데이터 세트를 기반으로 릿지와 라쏘 모델을 학습시켜봅시다. 물론 alpha값을 최적화합니다. 단 두개의 이상치만 제거했음에도 예측 성능이 매우 크게 향상됐습니다. 릿지의 경우 최적 alpha 값이 12에서 8로 변했습니다. GrLivArea 피처가 회귀 모델에서 차지하는 영향력이 크기에, 해당 피처의 이상치를 제거하는 것이 모델의 성능 개선에 큰 의미를 가졌습니다.
이처럼 회귀에 중요한 영향을 미치는 피처 위주로 이상치를 찾는 것은 중요합니다.

회귀 트리인 XGBoostRegressor 클래스와 LGBMRegressor 클래스를 이용하여 학습을 진행했습니다.

모델의 피처 중요도를 시각화한 결과입니다.

이번에는 개별 회귀 모델의 예측 결괏값을 혼합해 이를 기반으로 최종 회귀 값을 도출해봅시다. 앞에서 학습시킨 릿지와 라쏘 모델을 혼합했습니다. 최종 혼합 모델의 RMSE가 개별 모델의 RMSE보다 약간 개선됐습니다. 각 개별 모델에 부여하는 가중치를 정하는 특별한 기준은 없으며, 여러 시도를 통해 최적의 비율을 찾아야 합니다.

이번에는 XGBoost와 LightGBM을 혼합했습니다. 마찬가지로 혼합된 모델의 RMSE가 개별 모델의 RMSE 보다 약간 개선됐습니다.

앞서 소개한 스태킹 앙상블은 회귀에도 적용할 수 있습니다. 위의 메서드는 각 개별 모델을 학습하면서, 그 과정에서 메타 모델의 학습 데이터와 테스트 데이터를 생성하는 역할을 수행합니다.

스태킹 앙상블에 참여할 개별 모델은 릿지, 라쏘, XGBoost, LightGBM 총 4개입니다. 개별 모델이 반환하는 메타 모델의 학습 피처 데이터와 테스트 피처 데이터를 결합하여 메타 모델의 학습 및 테스트에 사용합니다.

메타 모델로 라쏘를 사용합니다. 메타 모델을 학습시키고, 최종 예측 및 RMSE를 측정합니다. 스태킹 회귀 모델은 테스트 데이터 세트에서 RMSE가 약 0.0979로 현재까지 가장 좋은 성능 지표를 기록했습니다. 스태킹 앙상블은 분류뿐만 아니라 회귀에서 특히 효과적으로 사용될 수 있는 모델입니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : PCA 실습 - UCI 신용카드 고객 데이터 세트 (0) | 2023.05.22 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 차원 축소 개요와 PCA(Principal Component Analysis) (0) | 2023.05.22 |
| 파이썬 머신러닝 완벽 가이드 : 자전거 대여 수요 예측 회귀 실습 (1) | 2023.05.13 |
| 파이썬 머신러닝 완벽 가이드 : 로지스틱 회귀와 회귀 트리 (0) | 2023.05.12 |
| 파이썬 머신러닝 완벽 가이드 : 선형 회귀 모델을 위한 데이터 전처리 (0) | 2023.05.12 |