
티스토리 뷰
많은 피처를 가진 데이터 세트를 PCA 변환한 뒤, 예측 영향도가 어떻게 되는지를 비교해봅시다. 사용할 데이터 세트는 UCI Machine Learning Repository에 있는 신용카드 고객 데이터 세트입니다.


신용카드 데이터 세트는 30,000개의 레코드와 24개의 피처를 가집니다. 이중 'default payment next month' 피처가 타겟값으로, '다음달 연체 여부'를 의미하며 연체일 경우 1, 정상납부일 경우 0입니다. 데이터 세트에서 "PAY_0" 피처 다음에 "PAY_2" 피처가 있으므로, "PAY_0"의 이름을 "PAY_1"로 바꿉시다. 타겟값의 이름도 너무 길어서 간단히 'default'로 변경합시다.

타겟값을 제외하고 총 23개의 피처가 있지만, 피치끼리의 상관성을 조사할 필요가 있습니다. DataFrame의 corr() 메서드를 이용해 피처 간의 상관도를 구한 뒤 seaborn의 heatmap으로 시각화합시다.
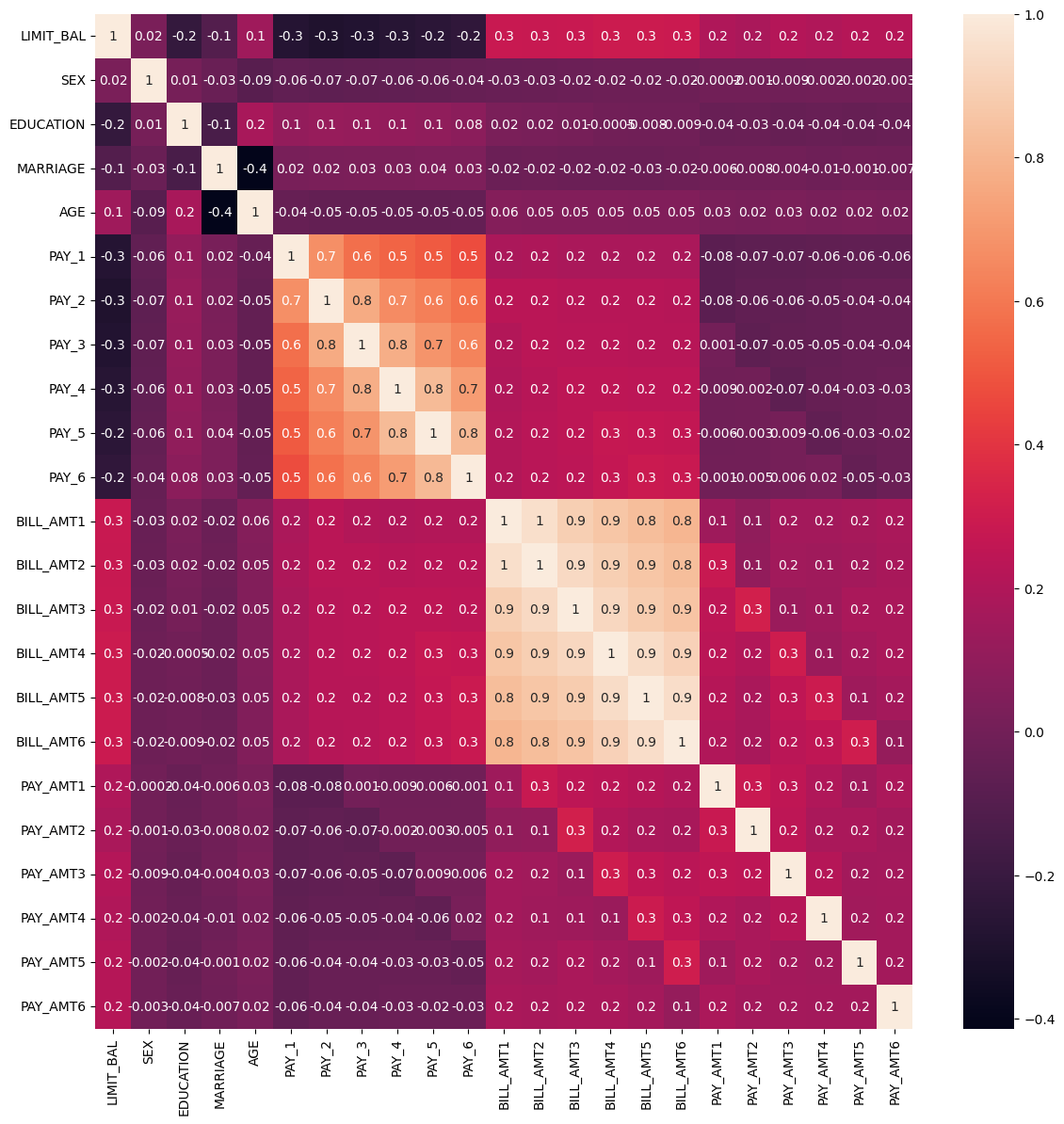
"BILL_AMT1" ~ "BILL_AMT6"까지 6개의 피처끼리의 상관도가 0.9 이상으로 매우 높음을 볼 수 있습니다. 이들만큼은 아니지만 "PAY_1" ~ "PAY_6"까지의 속성 역시 상관도가 높습니다. 이렇게 높은 상관도를 가진 속성들은 소수 개의 피처를 가지게끔 하는 PCA만으로도 자연스럽게 변동성을 수용할 수 있습니다. "BILL_AMT1" ~ "BILL_AMT6"까지의 6개의 피처를 2개의 피처로 PCA 변환한 뒤, 변환된 피처의 변동성을 확인해봅시다.

단 두개의 PCA 피처만으로도 6개의 피처의 변동성을 약 95% 이상 설명할 수 있으며, 특히 첫 번째 PCA 피처로 90%의 변동성을 수용할 정도로 6개 피처의 상관도가 매우 높음을 확인할 수 있습니다.
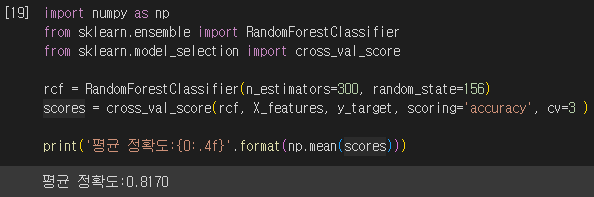

원본 데이터를 랜덤 포레스트 모델로 학습할 경우 교차 검증 정확도는 약 81.7%입니다. 23개의 피처를 PCA를 통해 단 6개의 피처로 압축한 데이터를 랜덤 포레스트 모델로 학습했을 때 교차 검증 정확도는 약 79.7%입니다. 전체 피처의 약 1/4 수준인 6개의 피처만으로도 원본 데이터를 기반으로 한 분류 에측 결과보다 약 1~2% 정도의 예측 성능 저하만 발생했습니다. 이는 PCA의 뛰어난 압축 능력을 잘 보여줍니다.
PCA는 차원 축소를 통해 데이터를 쉽게 인지하는 데 활용할 수 있지만, 이보다 더 활발하게 적용되는 영역은 컴퓨터 비전 분야입니다. 특히 얼굴 인식의 경우 Eigen-face라고 불리는 PCA 변환으로 원본 얼굴 이미지를 변환해 사용하는 경우가 많습니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : SVD(Singular Value Decomposition) (0) | 2023.05.23 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : LDA(Linear Discriminant Analysis) (0) | 2023.05.22 |
| 파이썬 머신러닝 완벽 가이드 : 차원 축소 개요와 PCA(Principal Component Analysis) (0) | 2023.05.22 |
| 파이썬 머신러닝 완벽 가이드 : 캐글 주택 가격 예측 (고급 회귀 기법) (1) | 2023.05.13 |
| 파이썬 머신러닝 완벽 가이드 : 자전거 대여 수요 예측 회귀 실습 (1) | 2023.05.13 |