
티스토리 뷰
결정 트리를 이용해 UCI 머신러닝 레포지토리에서 제공하는 사용자 행동 인식 데이터 세트에 대한 예측 분류를 수행해봅시다. 해당 데이터는 30명에게 스마트폰 센서를 부착시킨 뒤 여러 동작과 관련된 피처를 수집한 데이터입니다. 해당 피처를 바탕으로 어떤 동작인지를 예측해봅시다.

features.txt 파일에는 각 피처의 인덱스와 이름이 공백을 기준으로 분리되어 있습니다. 해당 파일을 DataFrame 객체로 만들어봅시다. 피처는 총 561개인 것을 확인할 수 있습니다. 또한 피처 이름을 보면 인체의 움직임과 관련된 속성의 평균/표준편차가 X, Y, Z축에 따라 계산된 결과임을 알 수 있습니다.
주의해야 할 점은, 561개의 피처 중 중복되는 피처 이름이 있다는 사실입니다. 이후 피처 데이터 세트(dataframe)를 구축하는 과정에서 중복된 피처명이 있으면 오류가 발생하므로, 전처리를 통해 해결해야 합니다.

중복되는 피처는 총 42개이며, 각 피처당 몇 개의 중복 건수가 있는지를 그룹바이 기능으로 알아볼 수 있습니다.

중복되는 피처 명에 대해서 원복 피처명에 _1, _2, .. 등을 붙여주는 함수를 정의했습니다. 이 함수를 통해 그룹바이 및 aggregation 연산을 연습할 수 있습니다.

먼저 피처의 이름으로 그룹바이를 진행한 뒤, cumcount 연산을 수행했습니다. cumcount 연산은 각 원소에 대해, 해당 원소와 중복되는 원소가 이미 있었을 경우 이번 원소가 몇 번째 중복 데이터인지를 카운트하는 연산입니다. 위의 예시를 보면 cumcount의 동작 방식을 잘 파악할 수 있습니다. cumcount가 부여된 칼럼의 이름을 'dup_cnt'라고 지었습니다. 그리고 나면 데이터프레임에 각 칼럼(피처)의 이름이 남아있지 않습니다. 피처의 이름을 다시 붙이기 위해 그룹바이를 수행하기 전의 데이터프레임과 df.merge() 메서드를 통해 합쳐줬습니다. 두 데이터프레임을 합칠 경우 공통 열이 존재해야 하므로, 두 데이터프레임 모두 새로 인덱싱을 수행하여 공통 열을 만들었습니다. 그 후 중복되는 피처의 이름을 바꾸기 위해, 각 피처 별로 dup_cnt가 1 이상인 경우 그 피처 이름 뒤에 dup_cnt를 붙여줍니다.

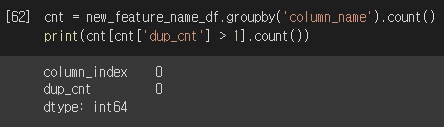
전처리를 완료하여 얻은 데이터프레임에 있는 561개의 피처 중, 서로 중복되는 이름의 피처는 더 이상 없는 것을 확인할 수 있습니다.

중복을 제거한 피처 이름을 바탕으로 학습/테스트 데이터 세트를 구성하여 반환하는 함수를 정의했습니다. 앞으로 사용자 행동 인식 데이터 세트로 실습을 많이 진행할 것이므로 해당 함수를 자주 사용할 것입니다.

학습 피처 데이터 세트의 정보를 보니, 총 7532개의 레코드가 존재하며 561개의 피처가 있습니다. 데이터 세트의 모든 값은 float 타입이므로 레이블 인코딩을 수행할 필요는 없습니다.

학습 레이블의 분포를 확인해보니, 각 레이블이 꽤 고르게 분포해있는 것을 확인할 수 있습니다.

결정 나무를 이용하여 바로 학습을 진행했습니다. 테스트 데이터에 대한 모델 예측의 정확도는 약 85%인 것을 확인할 수 있습니다.


cv_results_ 속성을 바탕으로 각 파라미터에 대한 mean_test_score를 확인해봤습니다. 결정 트리의 파라미터 중 하나인 max_depth의 값을 변경시킴에 따라 결정 트리의 예측 성능이 어떻게 변화하는 지를 GridSearchCV() 메서드를 이용해 확인했습니다. 7개의 후보 중, max_depth가 16일 때 검증 데이터 세트에 대한 평균 정확도가 가장 높았던 것을 보아, max_depth 값을 그 이상으로 높일 경우 과적합이 일어나 오히려 예측 성능이 저하된 것을 확인할 수 있습니다.

이번에는 min_samples_split을 16으로 고정하고, max_depth에 따른 테스트 데이터에 대한 정확도를 측정해봅시다. max_depth가 8일때 가장 높은 정확도를 기록했습니다.

max_depth, min_samples_split 두 파라미터에 대한 파라미터 최적화를 수행했을 때, 검증 데이터 세트에 대한 평균 정확도가 가장 높았을 때는 max_depth가 8, min_samples_split이 16일 때 입니다. 해당 파라미터로 학습 시킨 모델에 대한 테스트 데이터의 예측 성능을 약 0.87입니다.

결정 트리는 각 피처의 중요도를 feature_importances_ 속성에 기록합니다. 이를통해 규칙을 생성하는 데 있어서 핵심적인 피처가 무엇인지를 파악할 수 있습니다. seaborn 패키지로 각 피처에 대한 중요도를 내림차순 순으로 20개만 시각화한 결과입니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 그라디언트 부스팅 머신(GBM) (0) | 2023.05.02 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 앙상블 학습 (0) | 2023.05.02 |
| 파이썬 머신러닝 완벽 가이드 : 분류(Classfication)와 결정 트리 (0) | 2023.05.01 |
| 파이썬 머신러닝 완벽 가이드 : 피마 인디언 당뇨병 예측(Classification) (0) | 2023.04.30 |
| 파이썬 머신러닝 완벽 가이드 : 분류 모델의 평가 지표 (0) | 2023.04.30 |