
티스토리 뷰
분류를 수행하는 다양한 머신러닝 알고리즘이 있습니다(나이브 베이즈, 로지스틱 회귀, 결정 트리, 서포트 벡터 머신, 최소 근접 알고리즘, 신경망, 앙상블 등). 앙상블은 가장 각광을 받는 방법 중 하나입니다. 앙상블은 서로 같거나 다른 알고리즘을 결합하는 것입니다. 이미지, 영상, 음성, NLP 영역에서는 신경망에 기반한 딥러닝이 주류를 이루지만, 정형 데이터 분야에선 앙상블이 매우 높은 예측 성능을 보입니다.
앙상블은 일반적으로 배깅(Bagging)과 부스팅(Boosting) 방식으로 나뉩니다. 대표적인 배깅 알고리즘인 랜덤 포레스트는 준수한 예측 성능과 상대적으로 빠른 수행 시간, 유연성을 갖추어 많은 데이터 분석가들이 애용하는 알고리즘입니다.
하지만 최신 앙상블은 부스팅 방식을 주류로 발전되고 있습니다. 그라디언트 부스팅은 뛰어난 예측 성능을 보이지만, 수행 시간이 너무 오래 걸려 모델 튜닝에 많은 시간이 소요됩니다. 하지만 XgBoost(eXtra Gradient Boost)와 LightGBM 등 그라디언트 부스팅의 예측 성능을 유지한 채 수행 시간까지 단축 시킨 알고리즘이 등장하고 있습니다.
일반적으로 결정 트리는 앙상블의 기본 알고리즘으로 사용됩니다. 결정 트리는 원리가 간단하며 유연합니다. 또한 데이터의 스케일링이나 정규화 등의 사전 가공의 영향을 매우 적게 받습니다. 하지만 높은 예측 성능을 달성하기 위해선 많고 복잡한 규칙 구조를 가져야하며, 이로 인해 쉽게 과적합된다는 단점이 있습니다.
앙상블 기법에선 결정 트리의 이러한 단점이 오히려 장점으로 작용합니다. 앙상블에선 매우 많은 여러 개의 약한 학습기가 모여 확률적 보완과 오류에 대한 가중치 업데이트를 통해 예측 성능을 향상시키는데, 결정 트리가 매우 좋은 약한 학습기이기 때문입니다.
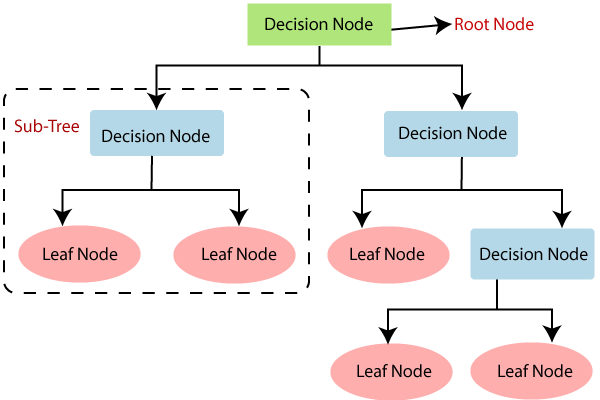
결정 트리는 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 알고리즘 입니다. 따라서 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 좌우합니다. 리프 노드는 결정된 클래스 값이며, 새로운 규칙 조건마다 서브 트리가 생성됩니다. 규칙이 많아진다는 것은 분류를 결정하는 방식이 복잡해진다는 뜻이고, 이는 곧 과적합으로 이어집니다. 즉, 트리가 깊어질수록 모델의 예측 성능이 저하될 가능성이 높습니다.
가능한 적은 규칙들(결정 노드들)로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 하는 규칙을 찾아야 합니다. 이는 곧 최대한 균일한 데이터 세트를 구성하도록 분할하는 규칙을 뜻합니다.

데이터 세트가 균일하다는 것이 어떤 의미인지를 알아봅시다. 위의 A, B, C 데이터 세트 중 가장 균일한 데이터 세트는 C입니다. 데이터 세트의 균일도는 데이터를 구분하는 데 필요한 정보의 양에 영향을 끼칩니다. C는 모두 같은 클래스의 데이터로 구성되어 있으므로 C에서 임의로 데이터를 뽑았을 때, 해당 데이터의 클래스를 매우 쉽게 알 수 있습니다. 하지만 A에서 임의로 데이터를 뽑았을 때, 해당 데이터의 클래스를 예측하는 데는 더 많은 정보가 필요합니다.
결정 트리는 정보 균일도가 높은 데이터 세트를 찾아 먼저 선택할 수 있는 규칙을 만듭니다. 정보의 균일도를 측정할 수 있는 대표적인 방법으로 엔트로피를 이용한 정보 이득 지수와 지니 계수가 있습니다.
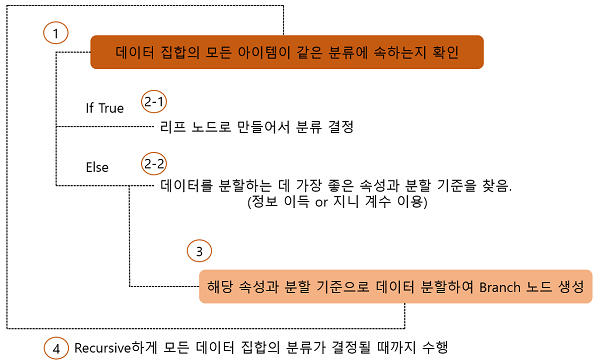
사이킷런에서 구현한 결정 트리는 기본적으로 지니 계수를 이용하여 규칙을 생성합니다. 지니 계수가 낮을수록 데이터 세트가 균일합니다. 결정 트리는 모든 데이터가 특정 분에 속할 때까지 지니 계수가 가장 낮은 조건을 찾아 트리를 반복적으로 분할하는 식으로 동작합니다. 그러므로 과적합에 취약합니다. 오히려 트리의 크기를 사전에 제한하는 것이 성능 향상에 도움이 되는 경우가 많습니다.
사이킷런은 결정 트리를 구현한 DecisionTreeClassifier(분류 모델) DecisionTreeRegressor(회귀 모델) 클래스를 제공합니다. 두 클래스의 파라미터는 아래와 같이 동일합니다. 각 파라미터의 값을 적절하게 조정하여 결정 트리의 과적합을 제어할 수 있습니다.
- min_samples_split : 노드를 분할하기 위한 최소 샘플 데이터의 수. 디폴트는 2.
- min_samples_leaf : 분할이 될 경우 왼쪽과 오른쪽 브랜치 노드가 가져야 할 최소 샘플 데이터의 수, 비대칭 레이블을 가지는 경우 애초에 특정 클래스의 데이터가 극도로 작을 수 있으니 값 설정 시 주의해야 함.
- max_features : 분할 규칙을 만들기 위해 고려하는 최대 피처 개수. 디폴트트는 None으로 모든 피처를 사용한다는 뜻. int 형일 경우 대상 피처의 개수이며, float일 경우 대상 피처의 퍼센트임. sqrt(auto), log 등도 있음.
- max_depth : 트리의 최대 깊이를 규정. 디폴트는 None이며, 이는 모든 데이터의 클래스를 완벽하게 분류할 때까지 트리를 분할한다는 뜻.
- max_leaf_nodes : 말단 노드의 최대 개수
결정 트리 모델이 데이터 세트에 대해 어떤 규칙들로 트리를 구축했는지를 시각적으로 보여주는 Graphviz 패키지가 있습니다. 해당 패키지는 원래 그래프 기반의 dot 파일로 기술된 다양한 이미지를 쉽게 시각화 해주는 패키지입니다. 본 리뷰에선 해당 패키지를 통한 실습 내용은 따로 담지 않겠습니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 앙상블 학습 (0) | 2023.05.02 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 결정 트리 실습 - 사용자 행동 인식 데이터 세트 (1) | 2023.05.01 |
| 파이썬 머신러닝 완벽 가이드 : 피마 인디언 당뇨병 예측(Classification) (0) | 2023.04.30 |
| 파이썬 머신러닝 완벽 가이드 : 분류 모델의 평가 지표 (0) | 2023.04.30 |
| 파이썬 머신러닝 완벽 가이드 : 사이킷런으로 해보는 타이타닉 생존자 예측 (0) | 2023.04.29 |