
티스토리 뷰
캐글 신용카드 사기 검출 분류 실습을 해봅시다. 해당 데이터 세트의 레이블인 "Class" 속성은 매우 불균형한 분포를 가집니다. 레이블 값은 0과 1로, 0이 정상이며 1이 사기 트랜잭션을 의미합니다. 전체 데이터의 0.172%만이 사기 트랜잭션 데이터입니다. 일반적으로 사기 검출이나 이상치 검출이 주제인 데이터 세트는 이처럼 레이블 분포가 극도로 불균형할 수 밖에 없습니다.
레이블 분포가 극도로 분균형할 경우 학습 후 예측 성능에 문제가 발생하는 경우가 많습니다. 이유는 당연히, 이상치 데이터가 정상 데이터에 비해 극도로 적기 때문입니다. 모델은 대부분의 경우 정상 데이터로 분류를 수행할 것입니다.
지도학습에서 이러한 문제를 해결하려면 적절한 학습 데이터를 확보해야 합니다. 대표적으로 오버 샘플링(Oversampling)과 언더 샘플링(Undersampling) 방법이 쓰이며, 보통 오버 샘플링이 예측 성능상 조금 유리한 경우가 많아 더 많이 사용됩니다.

언더 샘플링은 많은 데이터 세트를 적은 데이터 세트 수준으로 감소시키는 것입니다. 이렇게 한다면 모델이 정상 레이블로 과도하게 예측하는 경향을 없앨수 있지만, 전체 데이터 수 자체가 너무 적어져 버려 제대로 된 학습이 수행되지 않는다는 문제가 발생할 수 있습니다.
오버 샘플링은 적은 데이터 세트를 많은 데이터 세트 수준으로 증식시키는 것입니다. 같은 데이터를 단순히 복사하는 방식은 과적합 이슈로 인해 의미가 없으므로, 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식시킵니다. 대표적으로 SMOTE(Synthetic Minority Oversampling Technique) 방법이 있습니다. SMOTE는 적은 데이터 세트에 있는 개별 데이터들의 K 최근접 이웃을 찾아서, 그 데이터와 K개의 이웃들의 차이를 일정 값으로 만들어 기존 데이터와 약간 다른 새로운 데이터를 만들어냅니다. SMOTE를 구현하는 대표적인 파이썬 패키지는 imbalanced-learn이며, 실습 과정에서 사용해봅시다.

데이터 세트를 불러왔습니다. 각 V#으로 익명화 되어 있는 것을 확인했습니다. Time 피처는 데이터 생성 관련 작업용 속성으로서 큰 의미가 없기에 드랍하겠습니다.
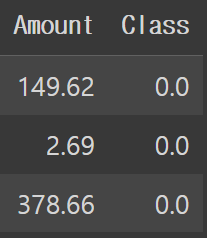
Amount 피처는 신용카드 트랜잭션 금액을 의미하며, Class 피처는 레이블로서 0이면 정상, 1이면 사기 트랜잭션임을 의미합니다. card_df.info()로 확인해보면 전체 284,807개의 레코드에서 결손값은 없으며, Class 피처만 int 형이고 나머지 피처는 모두 float 형인 것을 확인할 수 있습니다.

데이터 세트를 전처리하는 메서드를 따로 정의합시다. 원본 데이터 세트는 보존하기 위해, df_copy라는 객체에 원본 데이터 세트를 그대로 복사하고, 이 객체를 전처리한 뒤에 반환합시다. 일단은 'Time' 피처를 드랍했습니다.

데이터 세트를 학습과 테스트 데이터로 분리하는 메서드를 정의합시다. 전처리가 끝난 데이터를 학습과 테스트 데이터로 분리하면 됩니다. 학습 및 테스트 데이터의 레이블 분포를 비슷하게 맞춰줘야 합리적이므로, train_test_split() 메서드의 stratify 인자에 y_target을 지정해 분포를 비슷하게 데이터를 분리합시다.

학습 및 테스트 데이터의 레이블 분포를 확인해보니, 매우 비슷한 것을 볼 수 있습니다.

로지스틱 회귀 모델로 바로 학습을 진행해봤습니다. 분류 모델을 다양한 평가 지표로 평가하기 위해 만들어뒀던 get_clf_eval() 메서드로 모델의 예측 성능을 평가했습니다.

모델을 학습시키고 테스트 데이터에 대해 예측 성능을 평가하는 루틴을 하나의 메서드로 만들었습니다.
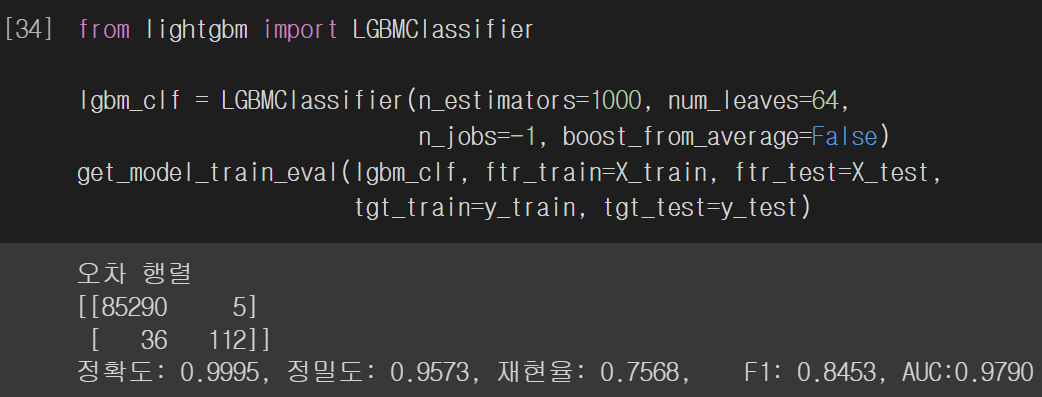
LightGMB Classifier 모델로 학습을 진행해봅시다. 모든 평가 지표에 대해 로지스틱 회귀 모델보다 더 좋은 성능을 기록했습니다. 극도로 불균형한 레이블 분포를 가진 데이터 세트를 LGBMClassifier 객체로 학습시킬 때 객체의 boost_from_average 인자를 반드시 False로 설정해야 합니다. 해당 인자의 디폴트 값은 True인데, True인 경우 재현률 및 ROC-AUC 값이 매우 저하됩니다.
이번에는 왜곡된 분포를 가지는 피처를 전처리한 뒤에 모델의 성능을 다시 평가해봅시다. 'Amount' 피처는 트랜잭션의 금액으로, 각 트랜잭션이 사기인지 아닌지를 판단하는데 매우 중요할 것으로 예측됩니다. 'Amount' 피처의 분포를 살펴보겠습니다.

Amount가 1000불 이하인 데이터가 대부분인 것을 확인할 수 있습니다. xticks를 설정할 때 rotation를 조정하여 x값들을 기울여서 표시했습니다. 기울이지 않는다면 글씨가 겹쳐보입니다. 그래프 시각화 시 bins 인자는 시각화할 x값의 개수이며, kde 인자는 Kernal Density Estimation을 의미합니다. 샘플안에 없는 데이터를 추정하여 존재할 구간안에 그 값이 존재할 확률을 시각화해줍니다. 전체적인 분포가 정규분포와 유사하므로, 'Amount' 피처를 그냥 정규분포로 변환시켜봅시다.

'Amount' 피처를 정규분포화 시키기 위해 전처리 메서드를 수정합시다. StandardScaler API를 이용하면 됩니다. 변환된 칼럼을 데이터 세트의 첫 번째 칼럼 위치에 삽입하고, 기존 'Amount' 피처는 드랍합시다.

'Amount' 피처를 전처리 한 데이터로 앞의 두 모델을 다시 학습시켰습니다. 로지스틱 회귀 모델과 LightGBM 두 모델 모두 정밀도와 재현율은 오히려 저하되었습니다.
정규분포로 전처리하는 대신 로그 변환을 수행해봅시다. 로그 변환은 데이터 분포도가 심하게 왜곡되어 있을 경우 적용하는 중요 기법 중 하나입니다. 값에 log를 취해 큰 값을 상대적으로 작은 값으로 변환하므로 데이터 분포도의 왜곡을 상당 수준 개선해줍니다.
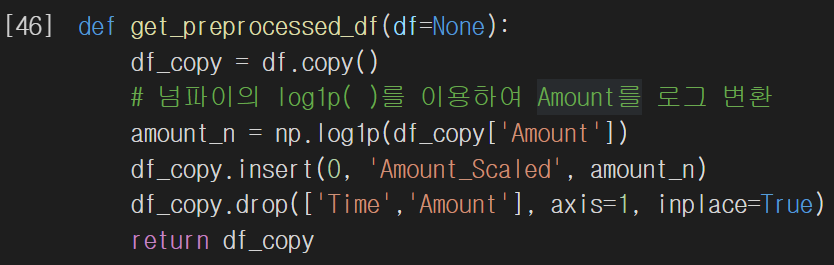
로그 변환은 넘파이의 log1p() 메서드를 이용하면 됩니다. 전처리 메서드를 이에 맞춰 수정합시다.

log 변환을 시킨 데이터로 두 모델을 다시 학습시킵니다. 로지스틱 회귀 모델은 변환 전보다 정밀도는 향상되었지만 재현율은 저하되었습니다. LightGBM 모델은 재현율이 향상되었습니다. 레이블이 극도로 불균형한 데이터 세트에 대해, 로지스틱 회귀는 데이터 변환 시 약간은 불안정한 예측 성능을 보이고 있습니다.
이번에는 이상치(Outlier)를 제거한 뒤 모델을 학습해봅시다. 이상치란, 전체 데이터의 패턴에서 벗어난 데이터입니다. 이상치는 머신러닝 모델 학습에 큰 영향을 끼칩니다. 그냥 드랍하는 것이 훨씬 좋은 경우가 대부분입니다. 데이터에서 이상치를 찾는 방법에 대해 알아봅시다.
이상치를 찾는 방법은 여러가지가 있지만, IQR(Inter Quantile Range) 방식을 이용해봅시다. IQR은 사분위(Quantile) 값의 편차를 이용하는 기법으로 흔히 박스 플롯으로 시각화할 수 있습니다.

사분위에 대해 먼저 알아봅시다. 사분위란, 전체 데이터를 내림차순으로 정렬하고 이를 1/4(25%)씩으로 분할하는 것을 말합니다.

이 중 25% ~ 75% 구간의 범위를 IQR이라고 합니다. 보통 Q3 + 1.5*IQR을 최댓값으로, Q1 - 1.5*IQR을 최솟값으로 설정한 뒤 이 밖에 있는 데이터를 이상치로 간주합니다.

그렇다면, 어떤 피처의 이상치를 제거할 것인지 선택해야 합니다. 많은 피처가 있을 경우, 레이블과의 상관성이 높은 피처를 위주로 이상치를 제거하는 것이 좋습니다. 모든 피처들의 이상치를 제거하는 것은 시간이 많이 소요되며, 레이블과 상관성이 낮은 피처는 이상치를 제거해도 성능 향상에 매우 미미한 영향을 끼칩니다.

피처 DataFrame의 corr() 메서드를 이용해 피처별 상관도를 구한 뒤 seaborn의 heatmap으로 시각화하여 이상치를 제거할 피처를 선택합시다. 히트맵의 cmap 인자를 'RdBu'로 설정하여 양의 상관관계가 높을수록 진한 파란색으로, 음의 상관관계가 높을수록 진한 빨간색으로 시각화합니다. 히트맵을 시각화 할 시 figsize를 작게 설정했더니 모든 피처 끼리의 상관성이 시각화되지 않았으므로 이를 주의합시다. 레이블과 상관성이 가장 높은 피처는 V14, V17인 것을 확인할 수 있습니다.
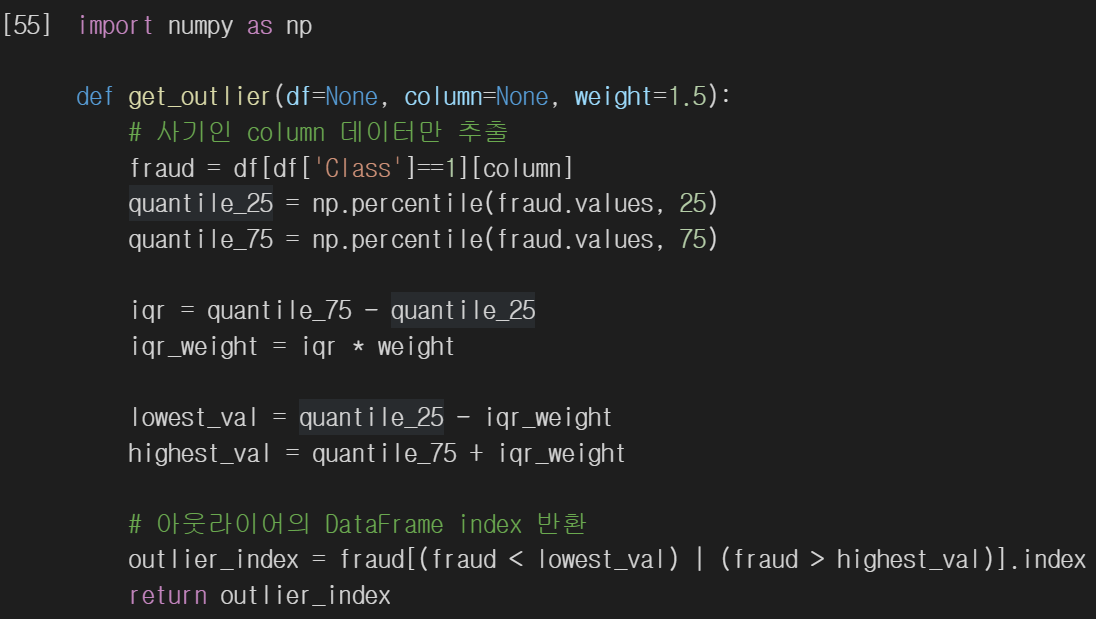
데이터프레임에서 특정 피처의 이상치 레이블의 인덱스를 반환하는 메서드를 정의합시다. 이때, 사기 레이블에 해당하는 레코드에 대해서만 이상치를 검출하고 있습니다. 이렇게 하는 이유는, 우리의 목표는 레이블이 1에 해당하는 데이터에 대한 정확도를 향상하는 것이기 때문입니다. 양성 레이블의 이상치를 제거함으로써 해당 레이블의 데이터에서 발생하는 잡음이나 오류를 줄여 모델이 양성 레이블 예측에 더 집중하도록 할 수 있습니다. 또한, 모든 데이터에 대해 이상치를 제거하면 양성 레이블의 데이터가 더욱 부족해질 수 있습니다. 사기에 해당하지 않는 레이블에 해당하는 데이터의 이상치도 제거했을 경우, 학습된 모델의 재현율이 매우 낮아지는 것을 확인했습니다.
넘파이의 percentile() 메서드를 통해 Q1, Q3 값을 구한 뒤, IQR, 최솟값, 최댓값을 계산합시다. 최댓값을 넘거나 최솟값에 미달하는 데이터의 인덱스를 반환합시다.

'V14' 피처의 이상치 인덱스를 추출했습니다. 총 4개의 이상치가 검출되었습니다.
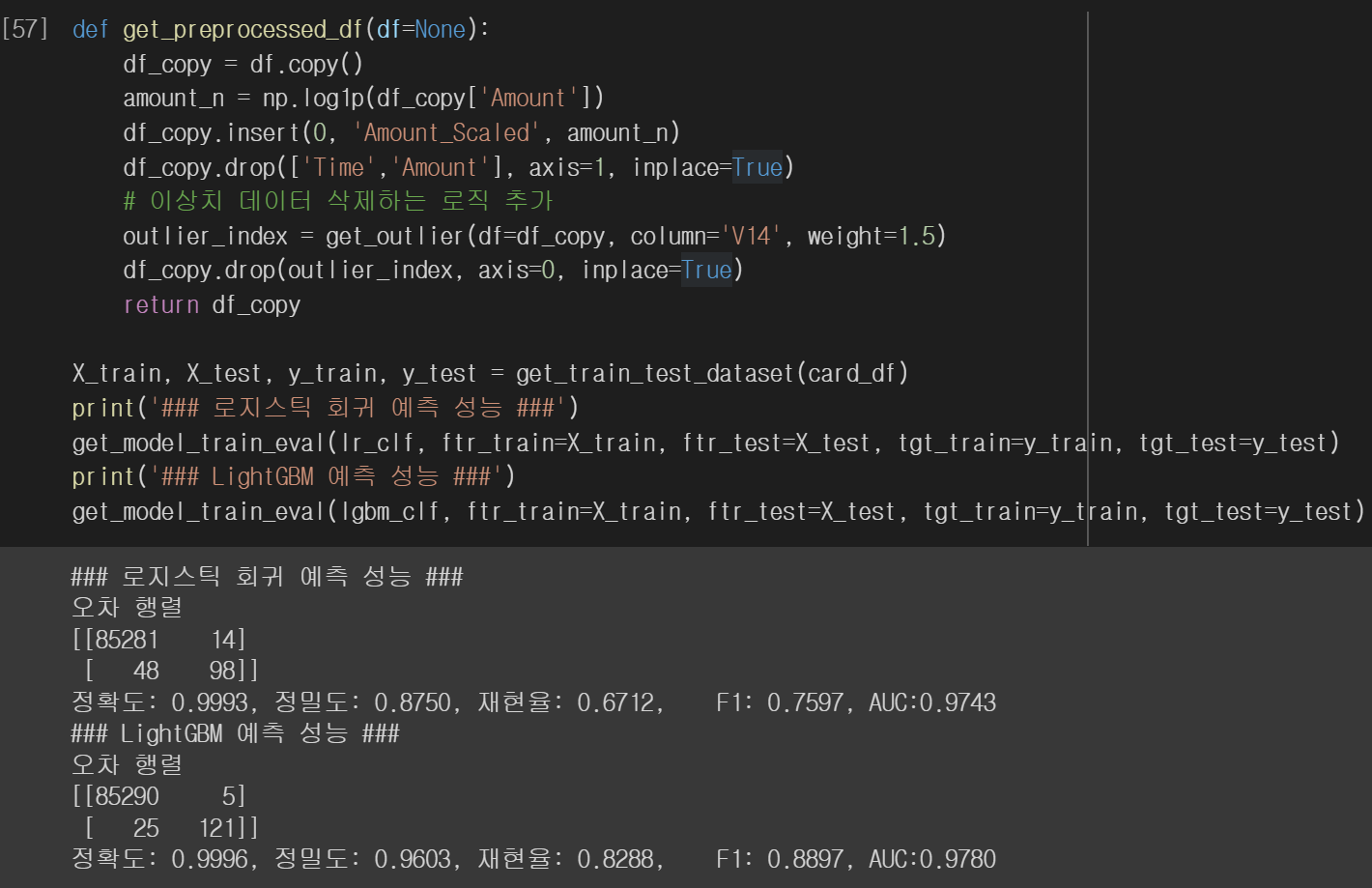
전처리 메서드에 'V14' 피처의 이상치를 제거하는 로직을 추가합시다. 'Amount' 피처에 대해선 로그 변환을 수행합니다. 전처리 된 데이터로 두 모델을 학습시킵니다. 데이터 4개만 제거했을 뿐인데 로지스틱 회귀 모델의 경우 재현율이 60.14%에서 67.12%로 크게 증가했으며, LightGBM 모델도 재현율이 76.35%에서 82.88%로 크게 증게했습니다.
이번에는 SMOTE 오버 샘플링을 적용한 뒤 두 모델을 다시 학습시켜봅시다. SMOTE를 적용할 때는 반드시 학습 데이터 세트만 오버 샘플링해야 합니다. 검증 데이터나 테스트 데이터를 오버 샘플링할 경우 결국 원본 데이터가 아닌 데이터 세트에서 검증 또는 테스트를 하는 것이기 때문에 올바른 검증 및 테스트가 아닙니다.

학습용 피처 및 레이블 데이터 세트를 SMOTE 객체의 fit_resample() 메서드를 통해 증식시킵니다. 데이터 증식 전 학습 데이터는 총 199,362건 이지만 증식 후 398,040건으로 약 두 배 가까이 데이터가 증식됐습니다. 또한 증식 후 두 레이블 모두 199020건 씩 존재합니다. 증식된 데이터 세트로 모델을 학습시켜봅시다.

로지스틱 회귀 모델을 학습시켰더니 재현율은 매우 높지만 정밀도가 약 5%로 매우 낮습니다. 오버 샘플링으로 생성된 너무나 많은 사기 레이블 데이터를 학습하면서 테스트 데이터에 대해 사기 레이블로 지나치게 예측을 수행한 결과입니다. 분류 결정 임곗값에 따른 정밀도와 재현율 곡선을 통해 SMOTE로 학습된 로지스틱 회귀 모델에 어떤 문제가 있는지 확인해봅시다.

임곗값이 0.99 이하에서는 재현율이 매우 좋고 정밀도가 극단적으로 낮습니다. 그 이상의 값에서는 반대 현상이 발생하고 있습니다. 임곗값 조정을 하더라도 민감도가 너무 심하여 올바른 재현율 및 정밀도 성능을 얻을 수 없으므로, SMOTE 적용 후 올바른 예측 모델을 얻지 못했다고 봐야합니다.

LightGBM 모델의 경우 재현율은 82.88%에서 84.93%로 상승했지만, 정밀도는 이전의 96.03%에서 91.18%로 저하되었습니다. SMOTE를 적용하면 일반적으로 재현율은 높아지나 정밀도는 낮아지기 때문입니다. 때문에 재현율이 정밀도 보다 중요한 태스크인 경우 SMOTE를 적용하면 좋습니다. 좋은 SMOTE 패키지일수록 재현율 증가율은 높이고, 정밀도 감소율은 낮추는 데이터를 만들어냅니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 회귀(Regression) (0) | 2023.05.10 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 스태킹 앙상블 (0) | 2023.05.07 |
| 파이썬 머신러닝 완벽 가이드 : XGBoost, LightGBM으로 캐글 산탄데르 고객 만족 예측해보기 (0) | 2023.05.05 |
| 파이썬 머신러닝 완벽 가이드 : 베이지안 최적화 기반의 하이퍼 파라미터 튜닝 (0) | 2023.05.03 |
| 파이썬 머신러닝 완벽 가이드 : LightGBM (0) | 2023.05.03 |