
티스토리 뷰
판다스는 DataFrame과 Series끼리 데이터 셀렉션 기능이 달라지는 부분이 있어 주의가 필요합니다. 넘파이의 경우 [] 연산자 내 단일 값 추출, 슬라이싱, 팬시 인덱싱, 불린 인덱싱을 통해 데이터를 추출합니다. 판다스는 iloc[], loc[] 연산자가 이와 같은 작업을 수행합니다. 먼저 판다스의 [] 연산자가 넘파이의 [] 연산자와 어떤 차이가 있는지를 알아보겠습니다.

DataFrame의 []연산자 안에 들어갈 수 있는 것은 칼럼명 문자(또는 리스트 객체), 또는 인덱스로 변환 가능한 표현식입니다. 인덱스로 변환 가능한 표현식이라는 의미는 추후에 다룰텐데, 현재 수준에서는 DataFrame의 [] 연산자는 칼럼만 지정할 수 있는 '칼럼 지정 연산자'로 이해하는 게 혼돈을 막는 가장 좋은 방법입니다.
또한, titanic_df[0] 또는 titanic_df[0, 0] 같은 표현은 오류를 발생시킵니다. 칼럼명이 아니기 때문이라고 이해하면 됩니다.

슬라이싱의 경우 원하는 결과를 반환합니다만, 혼동 방지를 위해 이러한 표현은 쓰지 않는 것이 좋습니다.

불린 인덱싱은 가능되며, 실제로 매우 유용하게 사용됩니다. 요약하자면, DataFrame의 []연산자는 칼럼 지정 또는 불린 연산을 할 때만 사용된다고 볼 수 있습니다. 슬라이싱 연산은 가능하긴 하지만 사용을 자제합시다.
DataFrame의 iloc[] 연산자에 로우와 칼럼의 위치를 지정하여 데이터를 선택할 수 있습니다. iloc[]은 위치 기반 인덱싱만 허용하기 때문에 행과 열의 좌표 위치에 해당하는 값으로 정숫값 또는 정수형의 슬라이싱, 팬시 리스트만 입력해줘야 합니다.
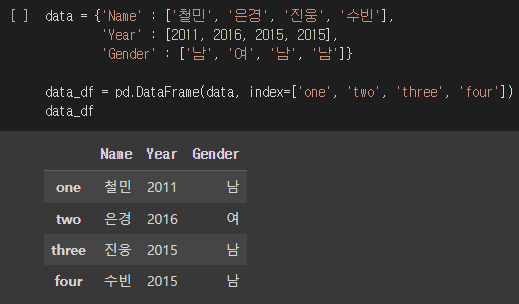
iloc[] 연산자를 써보기 위해 간단한 DataFrame을 생성했습니다.
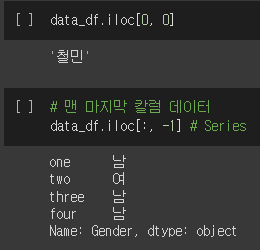
iloc[] 연산자 안에 칼럼의 이름이나 인덱스 값('one' 등)을 지정하면 오류가 발생합니다.

iloc[] 연산자의 결괏값은 단일 값, Series, DataFrame입니다. 하나의 칼럼만 추출했다면 Series, 다수의 칼럼을 추출했다면 DataFrame입니다. 또한, iloc[] 연산자는 불린 인덱싱을 제공하지 않습니다.
DataFrame의 loc[] 연산자는 명칭(Label) 기반으로 데이터를 추출합니다. 행 위치에는 인덱스 값을, 열 위치에는 칼럼명을 입력하여 데이터를 추출합니다.


loc[] 연산자에 슬라이싱을 적용할 때 유의해야 할 사항이 있습니다. 일반적으로 슬라시이싱을 '시작값:종료값'과 같이 지정하면 시작값 ~ 종료값-1까지의 범위를 의미합니다. 하지만 loc[]에 슬라이싱을 적용하면 종료값-1이 아니라 종료값까지 포함하는 것을 의미합니다. 이는 명칭 기반 인덱싱의 경우, 명칭은 숫자형이 아닐 수 있기 때문에 종료값-1이라는 연산이 정의되지 않기 때문입니다.

loc[] 연산자는 불린 인덱싱도 지원합니다. 즉, 불린 인덱싱은 iloc[] 연산자에서만 사용 불가능합니다.

실제로 동일한 불린 인덱싱을 [] 연산과 loc[] 연산에서 수행할 수 있습니다. 여기서 loc[] 연산에서 ['Name', 'Age']는 칼럼 위치에 놓여야함을 주의합시다.

복합 조건을 통한 불린 인덱싱은 &(and), |(or), ~(not) 연산자를 통해 표현 가능합니다.
'파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 : 사이킷런 기반 프레임워크 익히기 (0) | 2023.04.28 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 : 사이킷런 - 붓꽃 품종 예측하기 (0) | 2023.04.28 |
| 파이썬 머신러닝 완벽 가이드 : Pandas (3) (0) | 2023.04.28 |
| 파이썬 머신러닝 완벽 가이드 : Pandas (1) (0) | 2023.04.05 |
| 파이썬 머신러닝 완벽 가이드 : Numpy (0) | 2023.04.04 |