
티스토리 뷰
1. Word embedding
word2vec이 나오기 이전에는 단어를 one-hot encoded vector로 단순하게 표현했다. 이런 방법들은 단어 간의 의미적인 유사성같은 정보를 담지 못한다. 반면 word2vec은 의미가 비슷한 단어끼리 임베딩 공간 상에서 비슷한 위치에 자리잡도록 학습한다. 그러면 emb($\cdot$)를 각 단어의 word2vec 임베딩이라고 할 때, emb(king) - emb(man) + emb(woman) = emb(queen)과 같은 additive compositionality도 가질 수 있다. 어떻게 이렇게 잘 매핑된 임베딩을 학습할 수 있을까?
word2vec은 분포 가설(distributional hypothesis) 하에 고안된 알고리즘이다. 분포 가설은 비슷한 의미의 단어들은 그 단어가 어떤 문맥 속에 있을 때 주변 단어 분포가 비슷하다는 철학이다. word2vec은 분포 가설을 기반으로 주변 단어의 분포를 보고 각 단어의 임베딩을 결정한다. 이런 방식으로 배운 임베딩을 분산 표현(distributed representation)이라고 한다.
word2vec 논문은 주변 단어 분포를 기반으로 단어의 임베딩을 학습하는 두 가지 방법(CBOW, Skip-gram)을 제안한다.
2. word2vec (CBOW)

CBOW(Continuous Bag of Words)은 $w_{i-2}, w_{i-1} , ... , w_{i+1}, w_{i+2}$ (주변 단어)를 가지고 $w_{i}$ (중심 단어)를 맞추는 태스크를 통해 단어의 임베딩을 배운다(방금은 예시를 위해 윈도우 크기를 임의로 $2$로 지정했다). 위 그림은 CBOW의 동작을 보여준다. $x_{nk}$는 각 주변 단어의 one-hot encoding 된 벡터이다 (이 그림에서 $k$가 뭘 뜻하는 인덱스인지는 잘 모르겠지만, 동작 설명에 있어 중요하지 않다). 학습 데이터셋의 vocab 크기가 $V$이므로, 이 벡터의 차원은 $\mathbb{R}^V$이다. 여기에 $W \in \mathbb{R}^{V \times N}$를 곱하여 hidden embedding으로 변환한다. 중요한 점은 $W \in \mathbb{R}^{V \times N}$은 모든 one-hot vector에 대해 똑같이 곱해진다는 것이다 (즉, 가중치 공유). $N$은 $V$보다 작게 설정한다.
모든 주변 단어에 대해 hidden embedding을 얻었다면, 이를 모두 더한 다음에 주변 단어의 개수로 나눠준다. 그 결과 얻은 임베딩 벡터가 $h_{i}$이다. $h_{i} \in \mathbb{R}^{N}$에 $W^{'} \in \mathbb{R}^{N \times V}$ 가중치를 곱하여 $y_{j} \in \mathbb{R}^{V}$를 얻는다. 우리는 $y_{j}$에 softmax를 취한 벡터가 $w_{i}$ (중심 단어)의 one-hot encoding 벡터가 되길 원하므로, 두 벡터 간의 cross-entropy loss로 모델을 학습시키면 된다.
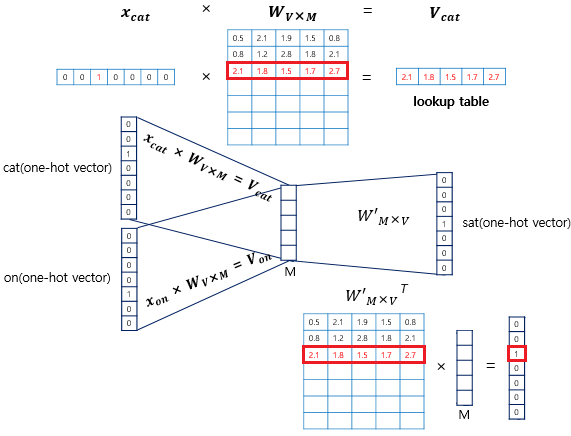
학습을 통해 얻은 각 벡터의 임베딩은 어디있는 걸까? 위 그림으로 설명 가능하다. one-hot vector에 곱해지는 가중치 행렬의 각 행(row)이 바로 각 단어에 대한 word2vec 임베딩이다. one-hot vector에서 $1$인 부분만 가중치 행렬의 특정 행을 활성화시키기 때문이다. 가중치 행렬에서 각 행을 가져오는 연산은 look-up table 이라고 한다.
그런데 사실 두 번째 가중치 행렬의 행 또한 각 단어의 word2vec 임베딩으로 사용할 수 있다. $h_{i}$와 각 행을 내적한 결과가 $y_{i}$의 각 원소를 구성한다. 결국 주변 단어들의 전체적인 문맥($h_{i}$)과 실제 중심 단어의 임베딩(두 번째 가중치의 행)의 내적값이 커져야 하고, 중심 단어가 아닌 단어의 임베딩과의 내적값은 작아져야 한다.
이런 해석은 첫 번째 가중치 행렬의 각 행은 각 단어의 주변 단어로서의 임베딩을 뜻하고, 두 번째 가중치 행렬의 각 행은 각 단어의 중심 단어로서의 임베딩이 된다. 실제 word2vec 임베딩으로는 첫 번째 가중치 행렬을 더 많이 사용하는 것 같다.
보통 인터넷의 글들을 보면 CBOW, Skip-gram은 오직 한 종류의 임베딩(첫 번째 행렬)만 배우는 것처럼 설명을 하다가, negative sampling을 이용한 word2vec을 설명할 때 갑자기 각 단어는 두 가지 임베딩(중심 단어, 주변 단어로서)을 가진다고 취급한다. 그런데 사실 이러한 개념은 CBOW, Skip-gram 때부터 이미 존재했던 것이다.
3. word2vec (Skip-gram)

주변 단어들로 중심 단어를 예측하는 태스크를 푸는 CBOW와 달리, Skip-gram은 중심 단어로 주변 단어를 예측한다. 마찬가지로 자기 전후로 몇 개를 예측할 지가 윈도우 크기이다.
Skip-gram의 데이터셋은 위와 같이 구성된다. 즉, cat을 모델에 줬을 때 the, fat, sat, on에 해당하는 one-hot element 부분이 모두 골고루 활성화 된 벡터를 뱉도록 만들어야 한다.
Skip-gram은 근본적으로 CBOW와 같은 모델을 쓴다. 그저 $h_{i}$가 주변 벡터들의 평균값이냐, 중심 단어냐의 차이이다. 그러므로 Skip-gram에서도 두 가중치 행렬 각각을 word2vec 임베딩으로 취급할 수 있다.
4. word2vec with Negative Sampling
기존 CBOW, Skip-gram에는 한 가지 문제점이 존재한다.
- vocab 사이즈가 매우 클 때, 두 번째 가중치 행렬이 커져서 계산시 bottleneck 문제 발생 (물론 첫 번째 가중치 행렬의 크기도 커진다).
- $y_{j}$의 softmax를 계산할 때 vocab에 있는 모든 단어를 고려한다. 이는 현재 sample (주변 단어, 중심 단어)와는 아무 관련 없는 단어에 대한 가중치까지 업데이트한다
이러한 문제의 근본적 원인은 모델에게 multi-class task를 풀게 시켰기 때문이다 (예 : $V$개의 단어 중, 중심 단어가 뭐야?). 이를 binary task (예 : 중심 단어가 $w_{i}$야?)로 바꿔주면 두 문제를 동시에 해결할 수 있다.
즉, 모델은 실제 중심 단어를 주고 중심 단어냐고 물어보면 yes를, 중심 단어가 아닌 단어를 주고 중심 단어냐고 물어보면 no를 잘 대답해야 한다. 여기서 중심 단어가 아닌 단어를 주는 학습 데이터를 negative sample이라고 부른다. 보통 negative sample은 전체 데이터셋에서 각 단어의 등장 빈도를 고려하여 샘플링한다. $P(w_i)$를 $w_i$의 등장 확률이라고 할때, $P'(w_i) = \frac{P(w_i)^{0.75}}{\sum_{j}^n P(w_j)^{0.75}}$를 실제 샘플링 함수로 사용한다. $P'(w_i)$는 $P(w_i)$에 비해, 등장 빈도가 매우 낮은 단어들이 샘플링 될 확률을 약간 올려준다.
"중심 단어가 $w_{i}$야?" 라는 질문에 대한 모델의 결과는 $h_{i} \cdot w_{i}$이다. 이는 두 번째 가중치 행렬에서 $w_{i}$의 임베딩에 해당하는 행만 가져오는 것과 같다. 그러므로 각 단어마다 중심 단어로서의 임베딩, 주변 단어로서의 임베딩을 미리 만들어 놓고 필요 연산에 가져다 쓰면 되는 것이다.

만약 Skip-gram이라면, $h_{i}$를 만들기 위해서 "cat"의 중심 단어 임베딩을 써야하고, "The", "fat", "pizza"는 주변 단어 임베딩을 가져와서 하나씩 내적하면 된다
'논문 리뷰' 카테고리의 다른 글
| 파이토치로 트랜스포머 구현하기 (0) | 2023.09.04 |
|---|---|
| Attention is all you need (0) | 2023.09.04 |